Jul 13, 2023
Enabling high availability for Klaw with NGINX
Announcing the availability of the high availability feature in Klaw, eliminating any single point of failure and ensuring minimal or no downtime.

Muralidhar Basani
|RSS FeedStaff Software Engineer at Aiven
Many organizations use Klaw, one of Aiven’s open source projects, to manage and govern Apache Kafka® ACLs and permissions in their environments. It is important to ensure that Klaw is fault tolerant and able to serve requests seamlessly and efficiently.
In a few organizations, Klaw is managing from 10 to 100s of Kafka clusters, and it is clear that the application is quite business critical and we need to understand the severity of downtime. This implies that Klaw should be made available on multiple replicated instances and run in failover mode or active/active.
Why high availability for Klaw?
Before diving into what high availability is, let's understand why it's crucial for Klaw. As Klaw is essential in managing and monitoring Kafka clusters, ensuring its resilience against potential failures is paramount. Downtime can have dire consequences ranging from slight inconveniences to lost revenue and a damaged reputation. High availability for Klaw addresses these critical issues:
- Minimizing downtime: By eliminating single points of failure and ensuring redundancy in the system, HA for Klaw minimizes or eliminates downtime.
- Scalability: As the workload increases, Klaw can handle a higher number of requests, catering to a growing user base, thanks to the HA configuration.
- Data availability: Ensuring that the data is always available, even in the case of component failures, is crucial. HA ensures the data is replicated across different servers, safeguarding against data loss.
- Service continuity: In the event of a disaster or system failure, HA ensures that there is no interruption in service and the operations continue without a hitch.
- Enhanced user experience: Consistent availability and reliability improve user experience, which is vital for customer satisfaction and retention.
Deploying Klaw at high availability
In version 2.4.0 and earlier, Klaw could not be deployed in a high availability setup due to architectural limitations in how Klaw managed its internal cache. This meant that Klaw could only be deployed as one instance in production or any environment.
Klaw stores most authorization-related data in the cache to avoid enormous database calls. This effectively reduces latency and gives users immediate response from the application.
To address this, the developer team behind Klaw introduced a feature that discovers all the available instances of Klaw which are deployed in high availability mode and resets the cache on those instances.
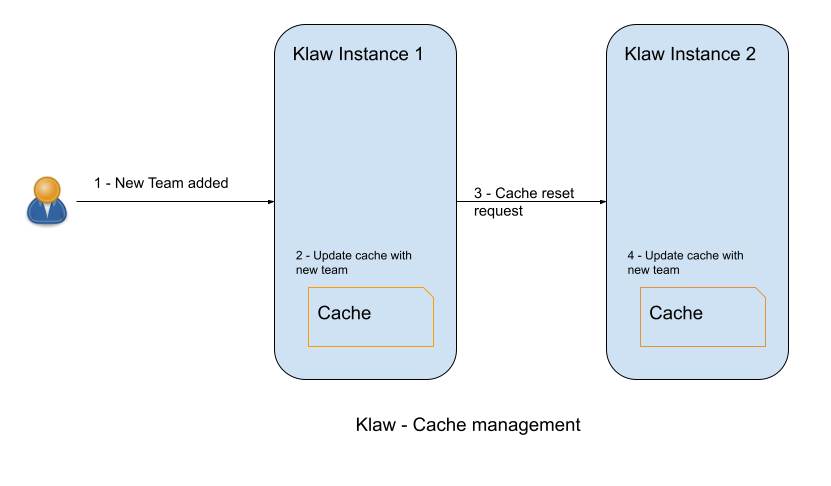
In the above example, a Klaw user adds (applies) a new team to instance 1. Klaw stores this information in its cache and triggers a new cache reset request on other instances which updates its local cache.
Klaw relies on its metadata which consists of users, teams, roles, permissions, clusters, environments and topics info. Klaw users can range from 50 to 500 or more users accessing the application requesting for topics, subscriptions, schemas and connectors daily. Handling all the requests with database queries is not efficient and database friendly. Hence, Klaw stores all information in its internal memory and resets it whenever there are changes requested. This allows Klaw to run seamlessly and serve the user’s requests without failure while querying real time data.
The benefits of high availability
You can learn more about the specific implementation patterns for using Klaw in high availability mode with NGINX as the load balancing server on the Klaw blog.
High availability provides the following benefits to you:
- Load balancing: Ensuring systems can handle higher workloads and substantial traffic. For example, 50,000 Kafka topics and ACLs on them with several back and forth requests requires load balancing to be performant.
- Fault tolerance: If a server within a cluster experiences a failure, a replicated server in a separate cluster can seamlessly take over the workload initially assigned to the failed server. This redundancy allows for failover, where a secondary component assumes the responsibilities of a primary component upon failure while minimizing any adverse effects on performance.
- Least connected balancing: Least-connected load balancing allows controlling the load on application instances more fairly in a situation when some of the requests take longer to complete.
Learn more
You can learn more about Klaw, an Aiven open source project for external management of Apache Kafka ACLs and configurations on the Klaw project website or GitHub organization. Feel free to open a GitHub issue if you have any issues with Klaw.
The Klaw team is one of many open source maintainer teams that Aiven's Open Source Programs Office helps maintain and sponsor. Aiven also works on PGHoard, a PostgreSQL® backup service and Karapace, an Apache Kafka® REST proxy.
If you want to try out Klaw or any of Aiven's other open source projects, we recommend signing up for a free trial of Aiven for Apache Kafka®.
Stay updated with Aiven
Subscribe for the latest news and insights on open source, Aiven offerings, and more.


