Dec 14, 2021
Explore the new SEARCH and CYCLE features in PostgreSQL® 14
Using recursive queries? Check out the new SEARCH and CYCLE features available in PostgreSQL 14 in this update to an earlier blog post.

Francesco Tisiot
|RSS FeedHead of Developer Experience at Aiven
Holidays, trips, happy times are always in our minds and a couple months ago we saw how to solve the knapsack problem using PostgreSQL recursive queries. However, blog posts don't always age like wine. Some weeks after the publication date, PostgreSQL 14 was announced, and it includes a couple of really interesting new features: CYCLE and SEARCH. They simplify the way we write recursive queries by a lot. This article gives a few examples, based on a favorite topic: trip planning!
Create the database
The examples in this post will work with any PostgreSQL 14 database, or newer. I'll be keeping things simple and using an Aiven-managed PostgreSQL service, with the Aiven CLI (check the dedicated documentation on how to install and log in). Here is the CLI command to create the database:
avn service create holidays-pg \ --service-type pg \ --plan hobbyist \ --cloud google-europe-west3 \ -c pg_version=14
The above creates a PostgreSQL 14 (-c pg_version=14) service named holidays-pg on the google-europe-west3 region, with the minimal hobbyist plan. That's enough for our test. To check which versions of the tools we provide, use the avn service versions command, documented in the dedicated page.
We have now a couple of minutes of waiting time for our PostgreSQL 14 database to be up and running. We can open our favorite travel guide and start browsing destinations. In the meantime, we can keep an eye on the progress of the service creation task with:
avn service wait holidays-pg
The above command will periodically request the state of the server till it starts. Once it returns, we're ready to connect to our holidays-pg PostgreSQL 14 service with:
avn service cli holidays-pg
Create the dataset
We want to travel across Europe, visiting some of the major cities within a budget. See how this is a variation of the knapsack problem discussed previously? It's always interesting how apparently different problems can be solved with a similar strategy.
To store the cities we want to visit, we create a cities table, and fill with the locations we've picked.
create table cities( city_id int primary key, city_name varchar ); insert into cities values (0, 'Rome'), (1, 'London'), (2, 'Paris'), (3, 'Helsinki'), (4, 'Barcelona');
How do we travel between cities? Easy, we head to a travel booking website and find the connections together with each trip cost. Usually we come back with a graph like this:
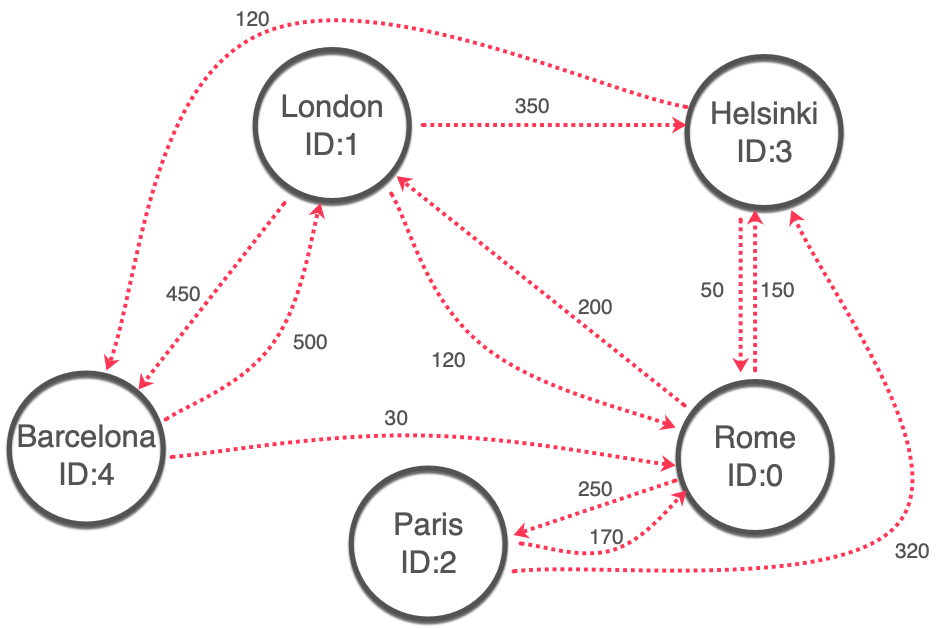
To represent the above information in PostgreSQL, we create a table named trips storing the information of source (city_a_id), destination (city_b_id) and trip cost in Euros (price_in_eur).
create table trips( trip_id int primary key, city_a_id int references cities(city_id), city_b_id int references cities(city_id), price_in_eur int ); insert into trips values (1, 0, 1, 200), (2, 0, 2, 250), (3, 0, 3, 150), (4, 1, 0, 120), (5, 1, 3, 350), (6, 1, 4, 450), (7, 2, 0, 170), (8, 2, 3, 320), (9, 3, 0, 50), (10, 3, 4, 120), (11, 4, 0, 30), (12, 4, 1, 500);
The trips table contains all available routes and the associated cost. For example, the trip with id 2 takes us from Rome (city_id:0) to Paris (city_id:2) for 250 euros. Not too bad, it's time to start planning the journey.
Plan the trip
Our journey needs to start somewhere, and since we know that every road leads to Rome, we can pick the eternal city as starting point. To check where we can travel to, we need a couple of joins between the cities and the trips tables.
select src.city_name, dst.city_name, trips.price_in_eur from cities src join trips on src.city_id = trips.city_a_id join cities dst on trips.city_b_id = dst.city_id where src.city_name='Rome';
The result shows the same information as the graph above: we can reach London, Paris and Helsinki with just one trip.
city_name | city_name | price_in_eur -----------+-----------+-------------- Rome | London | 200 Rome | Paris | 250 Rome | Helsinki | 150 (3 rows)
Add more hops to the journey
Ok, where next? We can use the power of recursive queries to loop over all the possible combinations.
With an infinite amount of money, we could travel the world forever. Translating this in database terms, it means that we could have endless loops in our recursive query. To mimic the real life and save us from infinite loops, let's set an overall budget of 800 euros to cover all our trips.
Learning from the previous post, we can write the recursive query for the journey like this:
with recursive trip_journey( city_id, trip_id, total_price_in_eur, journey_stops ) as ( select city_id as city_id, null::int as trip_id, 0 price_in_eur, ARRAY[city_name] as journey_name from cities where city_id=0 UNION ALL select trips.city_b_id, trips.trip_id, tj.total_price_in_eur + trips.price_in_eur, tj.journey_stops || city_b.city_name from trip_journey tj join trips on tj.city_id = trips.city_a_id join cities city_a on trips.city_a_id = city_a.city_id join cities city_b on trips.city_b_id = city_b.city_id where tj.total_price_in_eur + trips.price_in_eur < 800 ) select * from trip_journey;
Let's break it up a bit. The first section states the starting point: we want to start from Rome (city_id=0). If we don't travel, the trip_id is null and the overall cost is 0.
select city_id as city_id, null::int as trip_id, 0 price_in_eur, ARRAY[city_name] as journey_name from cities where city_id=0
Then we start adding trips, using the recursive piece, joining the previously defined trip_journey with the trips table to discover all possible destinations and associated cost.
UNION ALL select trips.city_b_id, trips.trip_id, tj.total_price_in_eur + trips.price_in_eur, tj.journey_stops || city_b.city_name from trip_journey tj join trips on tj.city_id = trips.city_a_id join cities city_a on trips.city_a_id = city_a.city_id join cities city_b on trips.city_b_id = city_b.city_id where tj.total_price_in_eur + trips.price_in_eur < 800
What is happening is that we take note of the journey by adding the city_b.city_name to the array of strings contained in journey_stops. Then, we calculate the total journey cost by summing the previous total and the current trip price (tj.total_price_in_eur + trips.price_in_eur). Finally we verify that the overall cost is within the 800 euros limit in the WHERE clause.
The query retrieves 89 rows, starting from the no trip option (staying in Rome) till the long {Rome,Helsinki,Rome,Helsinki,Rome,Helsinki,Barcelona,Rome} trip over multiple cities.
city_id | trip_id | total_price_in_eur | journey_stops ---------+---------+--------------------+----------------------------------------------------------------- 0 | | 0 | {Rome} 1 | 1 | 200 | {Rome,London} 2 | 2 | 250 | {Rome,Paris} 3 | 3 | 150 | {Rome,Helsinki} 0 | 4 | 320 | {Rome,London,Rome} 3 | 5 | 550 | {Rome,London,Helsinki} .... 4 | 10 | 770 | {Rome,Helsinki,Rome,Helsinki,Barcelona,Rome,Helsinki,Barcelona} 0 | 11 | 700 | {Rome,Helsinki,Rome,Helsinki,Rome,Helsinki,Barcelona,Rome} (89 rows)
Define the exploration path with the SEARCH option
The 89 rows above give us a good summary of all the possible itineraries we could take. But how is that dataset ordered? In PostgreSQL 14 the SEARCH option provides a new way to define how our recursive query should behave:
- If we want to order our trips based on the number of stops, we can use the
BREADTHoption. We'll see fist the trips involving 0 stops, then the ones involving 1 stop, 2 stops and so on. - If we want to order our trips based on the trip path, we can use the
DEPTHoption. We'll see the journey expanding at each step, e.g.{Rome}->{Rome->London}->{Rome->London->Helsinki}until the maximum depth of the journey is found, then it'll explore the consecutive brach of the tree.
To provide an example on our dataset, we just replace the last select * from trip_journey statement with the following:
SEARCH BREADTH FIRST BY city_id SET ordercol select * from trip_journey order by ordercol limit 15;
We are limiting the query to return only the first 15 rows (limit 15), this saves in computation since we're not going to scan the whole set of combinations but still enables us to demonstrate the feature. Because we're using the BREADTH option, the resultset is ordered by number of stops.
city_id | trip_id | total_price_in_eur | journey_stops | ordercol ---------+---------+--------------------+--------------------------------+---------- 0 | | 0 | {Rome} | (0,0) 1 | 1 | 200 | {Rome,London} | (1,1) 2 | 2 | 250 | {Rome,Paris} | (1,2) 3 | 3 | 150 | {Rome,Helsinki} | (1,3) 0 | 4 | 320 | {Rome,London,Rome} | (2,0) 0 | 9 | 200 | {Rome,Helsinki,Rome} | (2,0) 0 | 7 | 420 | {Rome,Paris,Rome} | (2,0) 3 | 5 | 550 | {Rome,London,Helsinki} | (2,3) 3 | 8 | 570 | {Rome,Paris,Helsinki} | (2,3) 4 | 6 | 650 | {Rome,London,Barcelona} | (2,4) 4 | 10 | 270 | {Rome,Helsinki,Barcelona} | (2,4) 0 | 9 | 600 | {Rome,London,Helsinki,Rome} | (3,0) 0 | 11 | 300 | {Rome,Helsinki,Barcelona,Rome} | (3,0) 0 | 9 | 620 | {Rome,Paris,Helsinki,Rome} | (3,0) 0 | 11 | 680 | {Rome,London,Barcelona,Rome} | (3,0) (15 rows)
The ordercol column contains a tuple (A,B) where the first item represents the level and the second the latest city_id. E.g. (2,0) states that the journey includes two trips, and ends in Rome (city_id=0), the same information can be found in the journey stops column containing {Rome,Paris,Rome}.
If now we replace the BREADTH clause with DEPTH, we get the first 15 trips ordered by the trip path, exploring with incremental steps how we can gradually increase our journey.
city_id | trip_id | total_price_in_eur | journey_stops | ordercol ---------+---------+--------------------+-----------------------------------------------------+------------------------------- 0 | | 0 | {Rome} | {(0)} 1 | 1 | 200 | {Rome,London} | {(0),(1)} 0 | 4 | 320 | {Rome,London,Rome} | {(0),(1),(0)} 1 | 1 | 520 | {Rome,London,Rome,London} | {(0),(1),(0),(1)} 0 | 4 | 640 | {Rome,London,Rome,London,Rome} | {(0),(1),(0),(1),(0)} 3 | 3 | 790 | {Rome,London,Rome,London,Rome,Helsinki} | {(0),(1),(0),(1),(0),(3)} 2 | 2 | 570 | {Rome,London,Rome,Paris} | {(0),(1),(0),(2)} 0 | 7 | 740 | {Rome,London,Rome,Paris,Rome} | {(0),(1),(0),(2),(0)} 3 | 3 | 470 | {Rome,London,Rome,Helsinki} | {(0),(1),(0),(3)} 0 | 9 | 520 | {Rome,London,Rome,Helsinki,Rome} | {(0),(1),(0),(3),(0)} 1 | 1 | 720 | {Rome,London,Rome,Helsinki,Rome,London} | {(0),(1),(0),(3),(0),(1)} 2 | 2 | 770 | {Rome,London,Rome,Helsinki,Rome,Paris} | {(0),(1),(0),(3),(0),(2)} 3 | 3 | 670 | {Rome,London,Rome,Helsinki,Rome,Helsinki} | {(0),(1),(0),(3),(0),(3)} 0 | 9 | 720 | {Rome,London,Rome,Helsinki,Rome,Helsinki,Rome} | {(0),(1),(0),(3),(0),(3),(0)} 4 | 10 | 790 | {Rome,London,Rome,Helsinki,Rome,Helsinki,Barcelona} | {(0),(1),(0),(3),(0),(3),(4)} (15 rows)
The ordercol now contains the concatenated list of city_ids, e.g. {(0),(1),(0),(2)} means we're going to travel Rome->London->Rome->Paris as confirmed by the journey_stops column. The order of rows returned follows the ordercol.
Avoid loops with the CYCLE option
Isn't the journey Rome->London->Rome->Paris beautiful? Ah, probably you don't like to pass multiple times by the same city. Loops are a very inefficient way of travelling, and we should avoid them when possible. Luckily, the PostgreSQL 14 CYCLE option provides a way to skip them.
In the original recursive query, replace the select * from trip_journey with:
CYCLE city_id SET is_cycle USING journey_ids select * from trip_journey where is_cycle=false;
The above adds to the recursive query a couple of columns:
journey_idscontaining the sequence ofcity_ids in anARRAYis_cycleflagging loops by checking if the currentcity_idis already in thejourney_idscolumn
The query result, filtered for is_cycle=false provides the list of all non looping trips we can afford with our budget.
city_id | trip_id | total_price_in_eur | journey_stops | is_cycle | journey_ids ---------+---------+--------------------+----------------------------------+----------+------------------- 0 | | 0 | {Rome} | f | {(0)} 1 | 1 | 200 | {Rome,London} | f | {(0),(1)} 2 | 2 | 250 | {Rome,Paris} | f | {(0),(2)} 3 | 3 | 150 | {Rome,Helsinki} | f | {(0),(3)} 3 | 5 | 550 | {Rome,London,Helsinki} | f | {(0),(1),(3)} 4 | 6 | 650 | {Rome,London,Barcelona} | f | {(0),(1),(4)} 3 | 8 | 570 | {Rome,Paris,Helsinki} | f | {(0),(2),(3)} 4 | 10 | 270 | {Rome,Helsinki,Barcelona} | f | {(0),(3),(4)} 4 | 10 | 690 | {Rome,Paris,Helsinki,Barcelona} | f | {(0),(2),(3),(4)} 4 | 10 | 670 | {Rome,London,Helsinki,Barcelona} | f | {(0),(1),(3),(4)} 1 | 12 | 770 | {Rome,Helsinki,Barcelona,London} | f | {(0),(3),(4),(1)} (11 rows)
After avoiding loops, we can also compare trips: for example, both the journeys {Rome,Helsinki,Barcelona,London} and {Rome,London,Helsinki,Barcelona} include in the same cities, but the first is 100 euros cheaper.
Return back home
There's a moment in every trip when you're happy to go back home, but, if you check the trips above, since we're avoiding loops, there is no way we'll end up in our lovely Rome again.
To achieve that, in the original query we need to factor in an additional join with the trips table, adding to each journey also the return cost to Rome, you can check the full query below:
with recursive trip_journey( city_id, trip_id, total_price_in_eur, journey_stops, journey_prices, return_price ) as ( select city_id as city_id, null::int, 0 price_in_eur, ARRAY[city_name] as journey_name, ARRAY[0::int] as journey_price, 0 return_price from cities where city_id=0 UNION ALL select trips.city_b_id, trips.trip_id, tj.total_price_in_eur + trips.price_in_eur, tj.journey_stops || city_b.city_name, tj.journey_prices || trips.price_in_eur, return_trips.price_in_eur from trip_journey tj join trips on tj.city_id = trips.city_a_id join cities city_a on trips.city_a_id = city_a.city_id join cities city_b on trips.city_b_id = city_b.city_id join trips return_trips on trips.city_b_id = return_trips.city_a_id and return_trips.city_b_id = 0 where tj.total_price_in_eur + trips.price_in_eur + return_trips.price_in_eur < 800 ) CYCLE city_id SET is_cycle USING journey_ids select * from trip_journey where is_cycle=false;
The join trips return_trips on trips.city_b_id = return_trips.city_a_id and return_trips.city_b_id = 0 section makes sure we are also including a return trip to Rome (city_id=0) and the tj.total_price_in_eur + trips.price_in_eur + return_trips.price_in_eur < 800 statement includes the return trip cost in the check against the budget.
The result shows all the 10 possible journeys which include in the budget a return trip to Rome.
city_id | trip_id | total_price_in_eur | journey_stops | journey_prices | return_price | is_cycle | journey_ids ---------+---------+--------------------+----------------------------------+-----------------+--------------+----------+------------------- 0 | | 0 | {Rome} | {0} | 0 | f | {(0)} 1 | 1 | 200 | {Rome,London} | {0,200} | 120 | f | {(0),(1)} 2 | 2 | 250 | {Rome,Paris} | {0,250} | 170 | f | {(0),(2)} 3 | 3 | 150 | {Rome,Helsinki} | {0,150} | 50 | f | {(0),(3)} 3 | 5 | 550 | {Rome,London,Helsinki} | {0,200,350} | 50 | f | {(0),(1),(3)} 4 | 6 | 650 | {Rome,London,Barcelona} | {0,200,450} | 30 | f | {(0),(1),(4)} 3 | 8 | 570 | {Rome,Paris,Helsinki} | {0,250,320} | 50 | f | {(0),(2),(3)} 4 | 10 | 270 | {Rome,Helsinki,Barcelona} | {0,150,120} | 30 | f | {(0),(3),(4)} 4 | 10 | 690 | {Rome,Paris,Helsinki,Barcelona} | {0,250,320,120} | 30 | f | {(0),(2),(3),(4)} 4 | 10 | 670 | {Rome,London,Helsinki,Barcelona} | {0,200,350,120} | 30 | f | {(0),(1),(3),(4)} (10 rows)
Wrapping up
The new SEARCH and CYCLE options provide a new and more elegant way of defining recursive queries behaviour. Some more resources to take this on board:
- WITH Queries (Common Table Expression) in PostgreSQL where you can find the
SEARCHandCYCLEdocumentation - Solving the knapsack problem in PosgreSQL where you can check how you can define search patterns and avoid cycles in previous PostgreSQL version
- Aiven for PostgreSQL to check Aiven offering for PostgreSQL as managed service.
Next steps
Your next step could be to check out Aiven for PostgreSQL. Just a thought.
If you're not using Aiven services yet, go ahead and sign up now for your free trial at https://console.aiven.io/signup!
In the meantime, make sure you follow our changelog and blog RSS feeds or our LinkedIn and Twitter accounts to stay up-to-date with product and feature-related news.
Further reading
Stay updated with Aiven
Subscribe for the latest news and insights on open source, Aiven offerings, and more.


