Mar 21, 2023
Does Apache Kafka® really preserve message ordering?
We’re told that Apache Kafka® preserves message ordering per topic/partition, but how true is that, and how close can we come to making it true?

Francesco Tisiot
|RSS FeedHead of Developer Experience at Aiven
One of Apache Kafka®'s most known mantras is "it preserves the message ordering per topic-partition", but is it always true? In this blog post we'll analyze a few real scenarios where accepting the dogma without questioning it could result in unexpected, and erroneous, sequences of messages.
Basic scenario: single producer
We can start our journey with a basic scenario: a single producer sending messages to an Apache Kafka topic with a single partition, in sequence, one after the other.
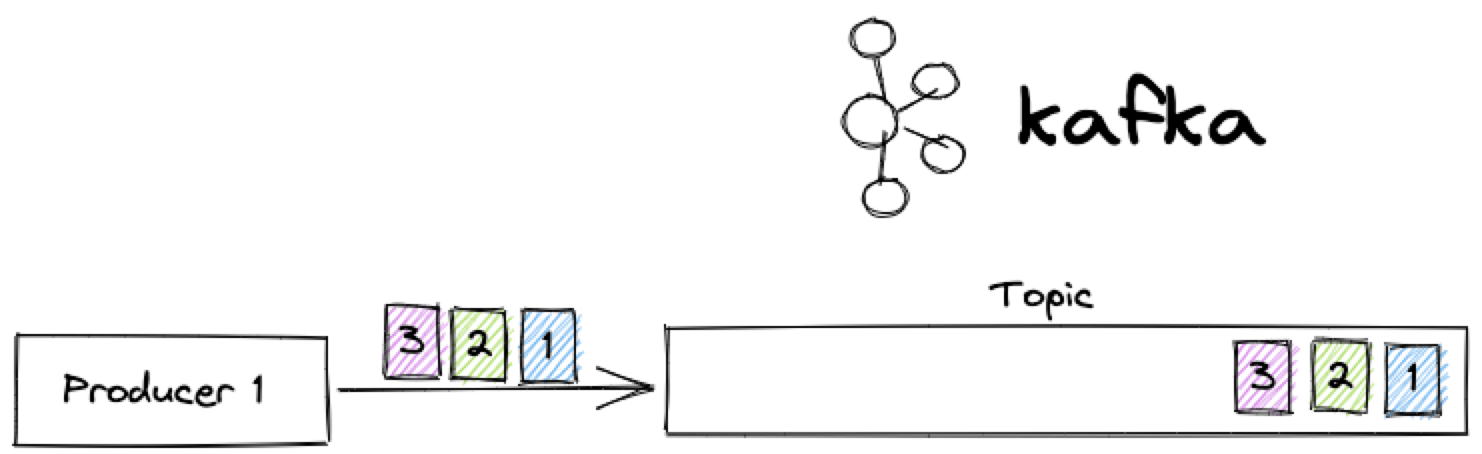
In this basic situation, as per the known mantra, we should expect an always correct ordering. But, is it true? Well... it depends!
The network is not equal
In an ideal world, the single producer scenario should always result in a correct ordering. But our world isn't perfect! Different network paths, errors and delays could mean that a message gets delayed or lost.
Let's imagine a situation below: a single producer, sending three messages to a topic:
- Message
1, for some reason, finds a long network route to Apache Kafka - Message
2finds the quickest network route to Apache Kafka - Message
3gets lost in the network
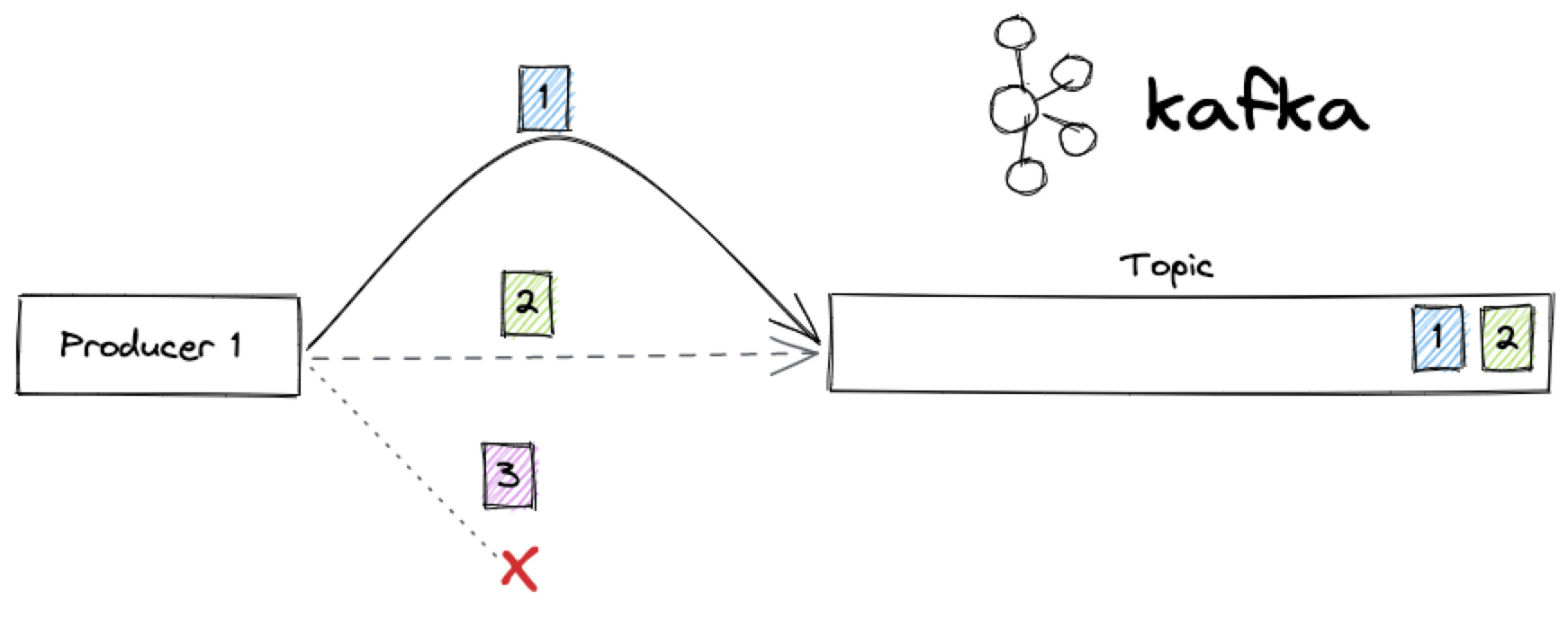
Even in this basic scenario, with only one producer, we could get an unexpected series of messages in the topic.
The end result on the Kafka topic will show only two events being stored, with the unexpected ordering 2, 1.
If you think about it, it's the correct ordering from the Apache Kafka point of view: a topic is only a log of information and Apache Kafka will write the messages to the log depending on when it "senses" the arrival of a new event. It's based on Kafka ingestion time and not on when the message was created (event time).
Acks and retries
But, not all is lost! If we look into the producing libraries (aiokafka being an example) we have ways to ensure that messages are delivered properly.
First of all, to avoid the problem with the message 3 in the above scenario, we could define a proper acknowledgment mechanism. The acks producer parameter allows us to define what confirmation of message reception we want to have from Apache Kafka.
Setting this parameter to 1 will ensure that we receive acknowledgment from the primary broker responsible for the topic (and partition). Setting it to all will ensure that we receive the ack only if both the primary and the replicas correctly store the message, thus saving us from problems when only the primary receives the message and then fails before propagating it to the replicas.
Once we set a sensible ack, we should set the possibility to retry sending the message if we don't receive a proper acknowledgment. Differently from other libraries (kafka-python being one of them), aiokafka will retry sending the message automatically until the timeout (set by the request_timeout_ms parameter) has been exceeded.
With acknowledgment and automatic retries, we should solve the problem for the message 3. The first time it is sent, the producer will not receive the ack, therefore, after the retry_backoff_ms interval, it will send the message 3 again.
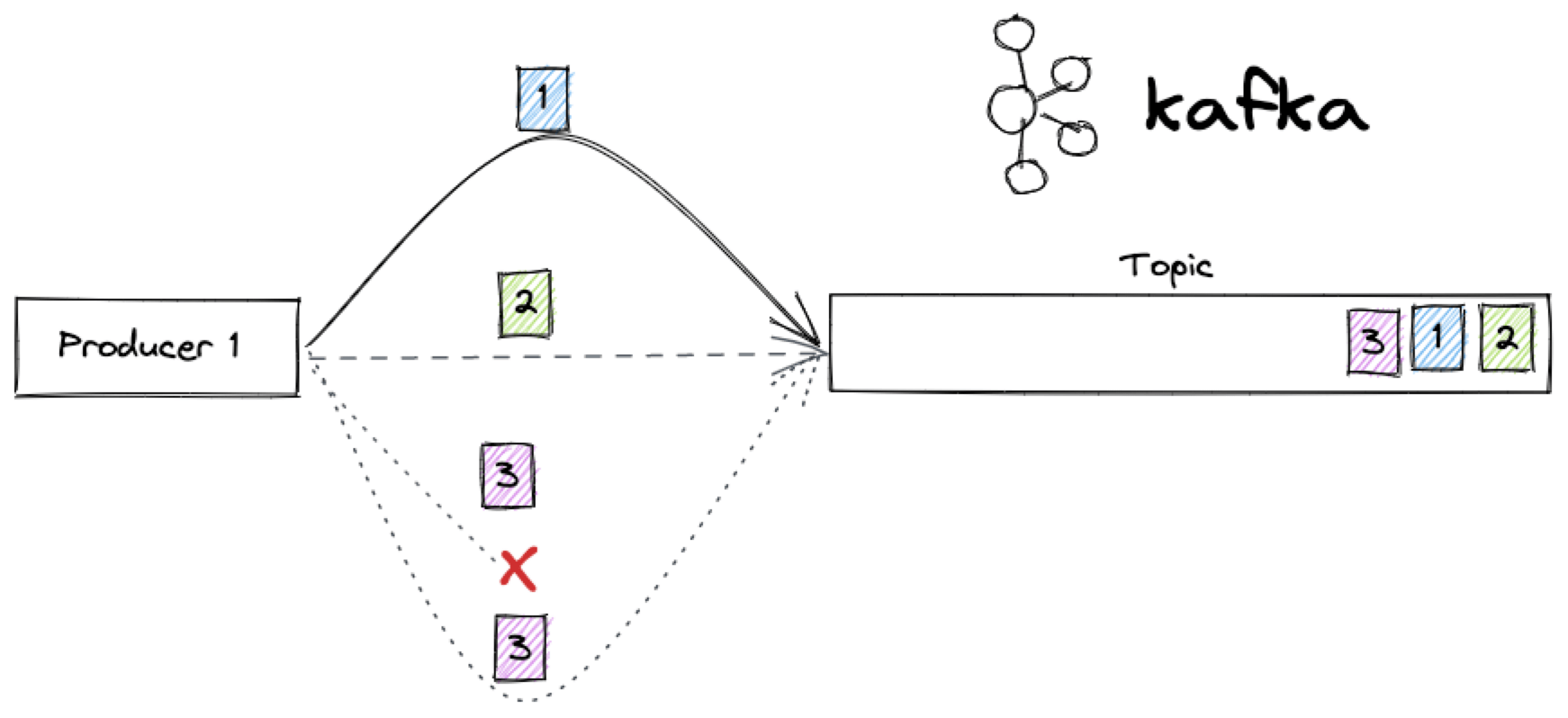
Max in flight requests
However, if you watch closely the end result in the Apache Kafka topic, the resulting ordering is not correct: we sent 1,2,3 and got 2,1,3 in the topic... how to fix that?
The old method (available in kafka-python), was to set the maximum in flight request per connection: the number of messages we allow to be "in the air" at the same time without acknowledgment. The more messages we allow in the air at the same time, the more risk of getting out of order messages.
When using kafka-python, if we absolutely needed to have a specific ordering in the topic, we were forced to limit the max_in_flight_requests_per_connection to 1. Basically, supposing that we set the ack parameter to at least 1, we were waiting for an acknowledgment of every single message (or batch of messages if the message size is less than the batch size) before sending the following one.
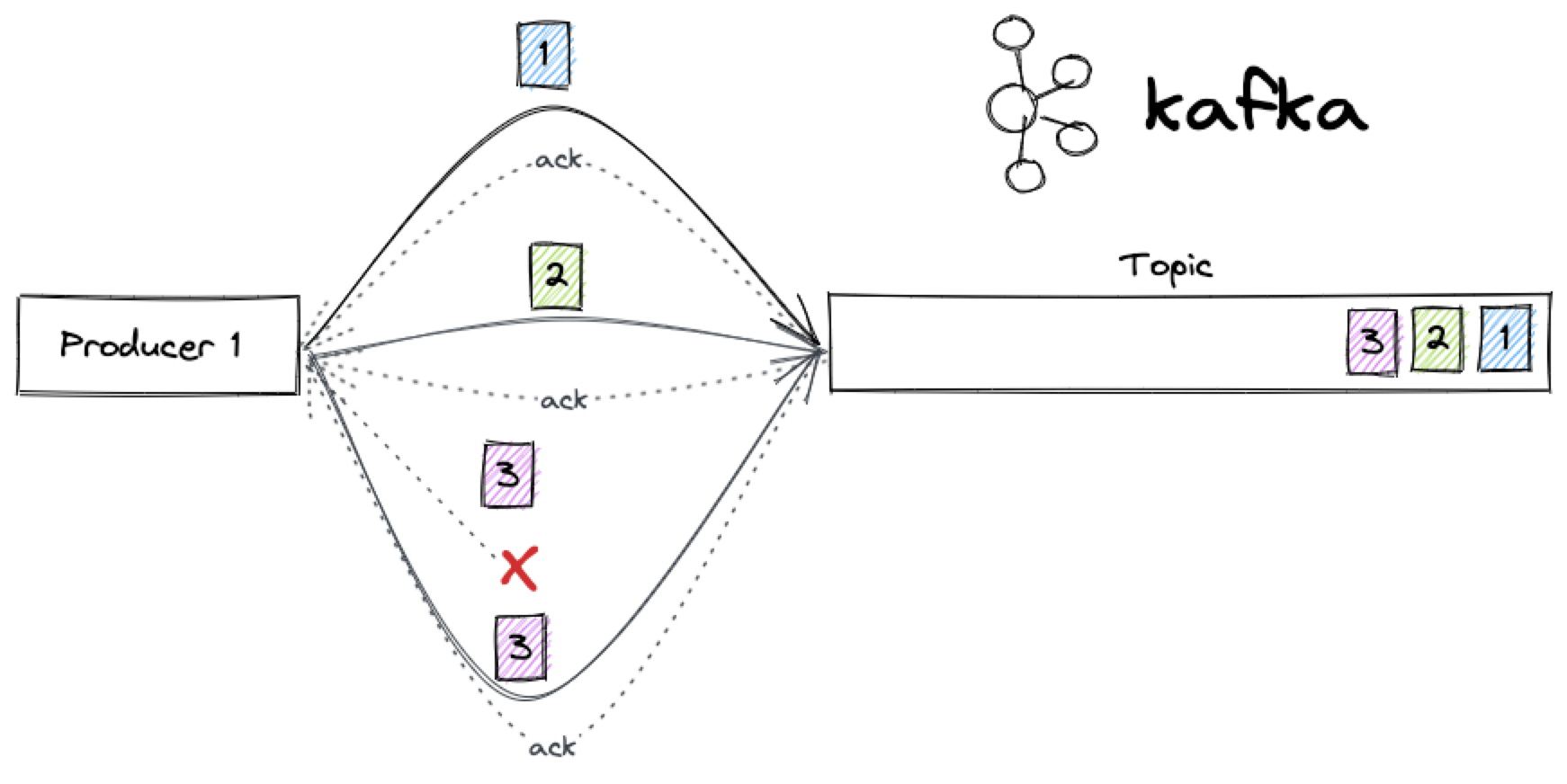
The absolute correctness of ordering, acknowledgment and retries come at cost of throughput. The smaller amount of messages we allow to be "in the air" at the same time, the more acks we need to receive, the less overall messages we can deliver to Kafka in a defined timeframe.
Idempotent producers
To overcome the strict serialization of sending one message at a time and waiting for the acknowledgement, we can define idempotent producers. With an idempotent producer, each message gets labelled with both a producer ID, and a serial number (a sequence maintained for each partition). This composed ID is then sent to the broker alongside the message.
The broker keeps track of the serial number per producer and topic/partition. Whenever a new message arrives, the broker checks the composed ID, and if, within the same producer, the value is equal to the previous number + 1, then the new message is acknowledged, otherwise it is rejected. This provides a guarantee of the global ordering of messages allowing a higher number of in flight requests per connection (maximum of 5 for the Java client).
Increase complexity with multiple producers
So far we imagined a basic scenario with only one producer, but the reality in Apache Kafka is that often the producers will be multiple. What are the little details to be aware of, if we want to be sure about the end ordering result?
Different locations, different latency
Again, the network is not equal, and with several producers located in possibly very remote positions, the different latency means that the Kafka ordering could differ from the one based on event time.
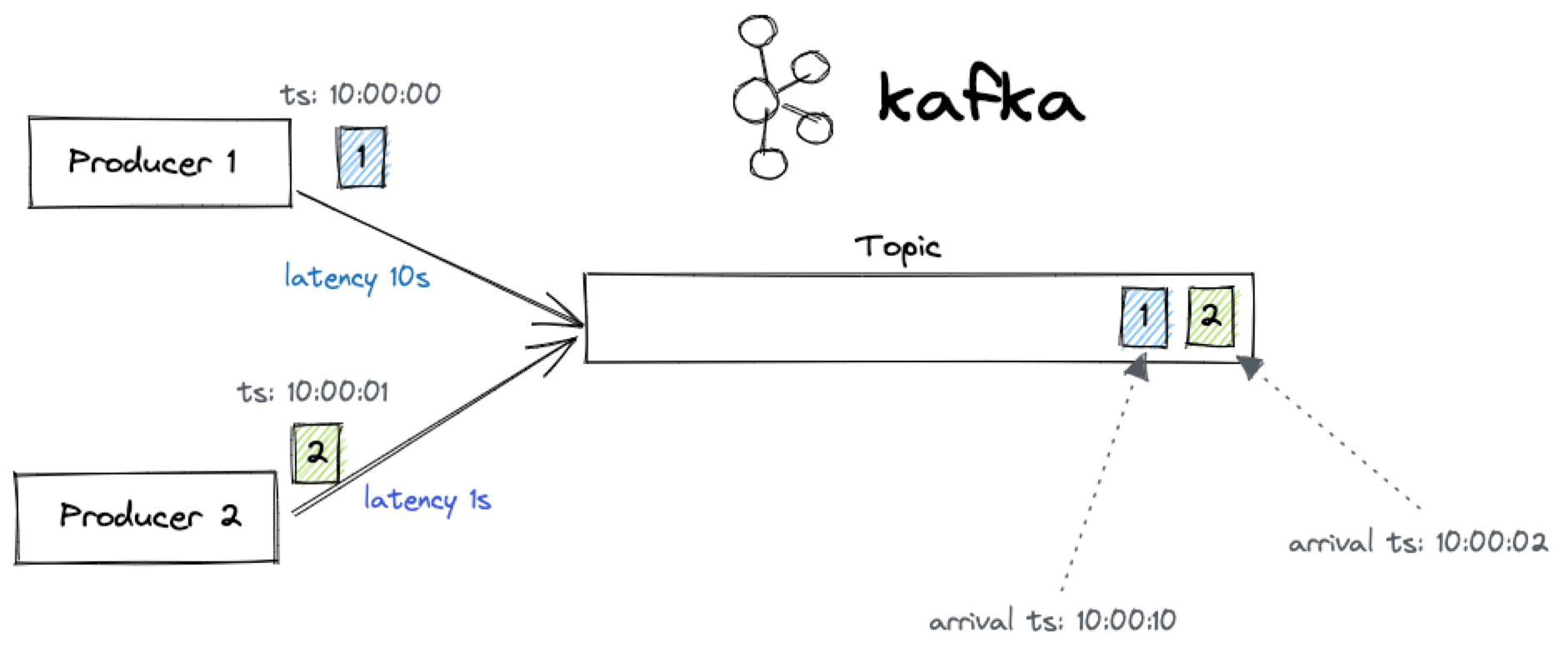
Unfortunately, the different latencies between different locations on earth can't be fixed, therefore we will need to accept this scenario.
Batching, an additional variable
To achieve a higher throughput, we might want to batch messages. With batching we send messages in "groups", minimizing the overall number of calls, and increasing the payload to overall message size ratio. But, in doing so, we can again alter the ordering of events. The messages in Apache Kafka will be stored per batch, depending on the batch ingestion time. Therefore, the ordering of messages will be correct per batch, but different batches could have different ordered messages within them.
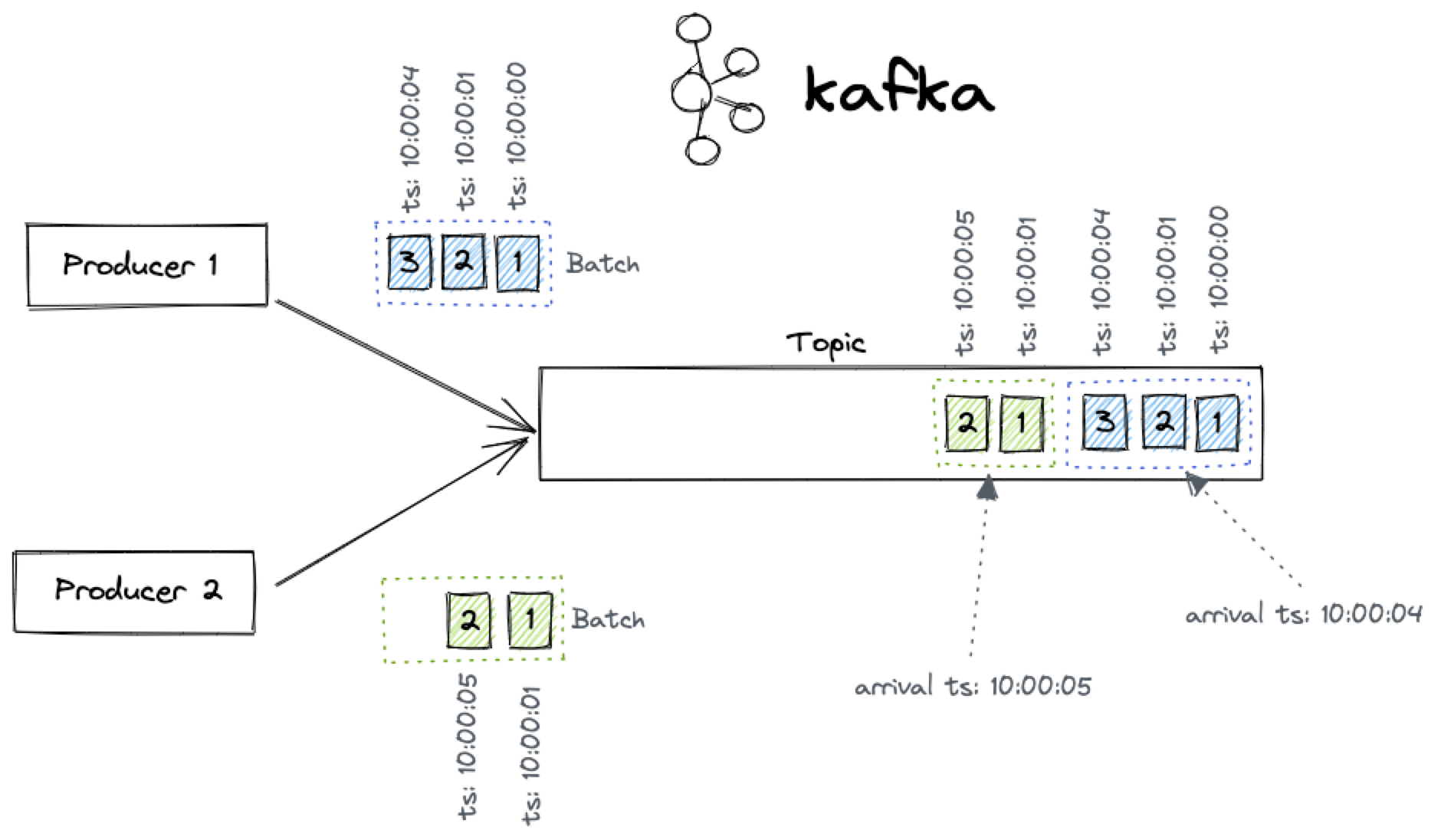
Now, with both different latencies and batching in place, it seems that our global ordering premise would be completely lost... So, why are we claiming that we can manage the events in order?
The savior: event time
We understood that the original premise about Kafka keeping the message ordering is not 100% true, the ordering of the messages depends on the Kafka ingestion time and not on the event generation time. But, what if the ordering based on event-time is important?
Well, we can't fix the problem on the production side, but we can do it on the consumer side. All the most common tools that work with Apache Kafka have the ability to define which field to use as event time, including Kafka Streams, Kafka Connect with the dedicated Timestamp extractor single message transformation (SMT) and Apache Flink®.
Consumers, when properly defined, will be able to reshuffle the ordering of messages coming from a particular Apache Kafka topic. Let's analyze the Apache Flink example below:
CREATE TABLE CPU_IN ( hostname STRING, cpu STRING, usage DOUBLE, occurred_at BIGINT, time_ltz AS TO_TIMESTAMP_LTZ(occurred_at, 3), WATERMARK FOR time_ltz AS time_ltz - INTERVAL '10' SECOND ) WITH ( 'connector' = 'kafka', 'properties.bootstrap.servers' = '', 'topic' = 'cpu_load_stats_real', 'value.format' = 'json', 'scan.startup.mode' = 'earliest-offset' )
In the above Apache Flink table definition, we can notice:
occurred_at: the field is defined in the source Apache Kafka topic in unix time (datatype isBIGINT).time_ltz AS TO_TIMESTAMP_LTZ(occurred_at, 3): transforms the unix time into the Flink timestamp.WATERMARK FOR time_ltz AS time_ltz - INTERVAL '10' SECONDdefines the newtime_ltzfield (calculated fromoccurred_at) as the event time and defines a threshold for late arrival of events with a maximum of 10 seconds delay.
Once the above table is defined, the time_ltz field can then be used to correctly order events and define aggregation windows, making sure that all events within the accepted latency are included in the calculations.
The - INTERVAL '10' SECOND defines the latency of the data pipeline, and is the penality we need to include to allow the correct ingestion of late arriving events. Please note, however, that the throughput is not impacted. We can have as many messages flowing in our pipeline as we want, but we're "waiting 10 seconds" before calculating any final KPI in order to make sure we include in the picture all the events in a specific timeframe.
An alternative approach, that works only if the events contain the full state, is to keep for a certain key (hostname and cpu in the above example) the maximum event time reached so far, and only accept changes where the new event time is greater than the maximum.
Wrapping up
The concept of ordering in Kafka can be tricky, even if we only include a single topic with a single partition. This post shared a few common situations that could result in an unexpected series of events. Luckily options like limiting the number of messages in flight, or using idempotent producers, can help achieve an ordering in line with expectations.
In the case of multiple producers, and the unpredictability of network latency, the option available is to fix the overall ordering on the consumer side by properly handling the event time that needs to be specified in the payload.
Some further readings:
Stay updated with Aiven
Subscribe for the latest news and insights on open source, Aiven offerings, and more.


