Building a real-time AI pipeline for data analysis with Apache Flink® and OpenAI
Make sense of social media data with Apache Kafka® and Apache Flink®
In today's fast-paced world, getting real-time insights is essential for businesses, researchers, and analysts. This article will guide you step by step through the process of building a real-time data analysis pipeline using Apache Kafka and Apache Flink. While doing so we'll explore the key components needed to process and enrich each record, analyze the data and visualize the results.
Additionally, we'll explore the use of a large language model (LLM) for data enrichment. We'll highlight the benefits and drawbacks of this approach in contrast to using various specialised models.
What data will we use?
Our data source will be social media records from Mastodon. Mastodon is a decentralized social media platform with convenient APIs and libraries for streaming records. Social media, with its diverse conversations and topics, becomes particularly interesting when aggregated and analyzed, making it the perfect basis for our playground.
What analysis will we perform?
We'll ask the following questions for each individual message:
- Does this record convey a positive, negative, or neutral sentiment?
- Which category or topic does this message belong to?
- Does the message contain any rude or inappropriate language?
- Does the message contain sarcasm?
- What is the language of the message?
With these data points, we can aggregate the data and examine correlations, such as the relationship between sentiment and categories or the link between a category and the likelihood of inappropriate language.
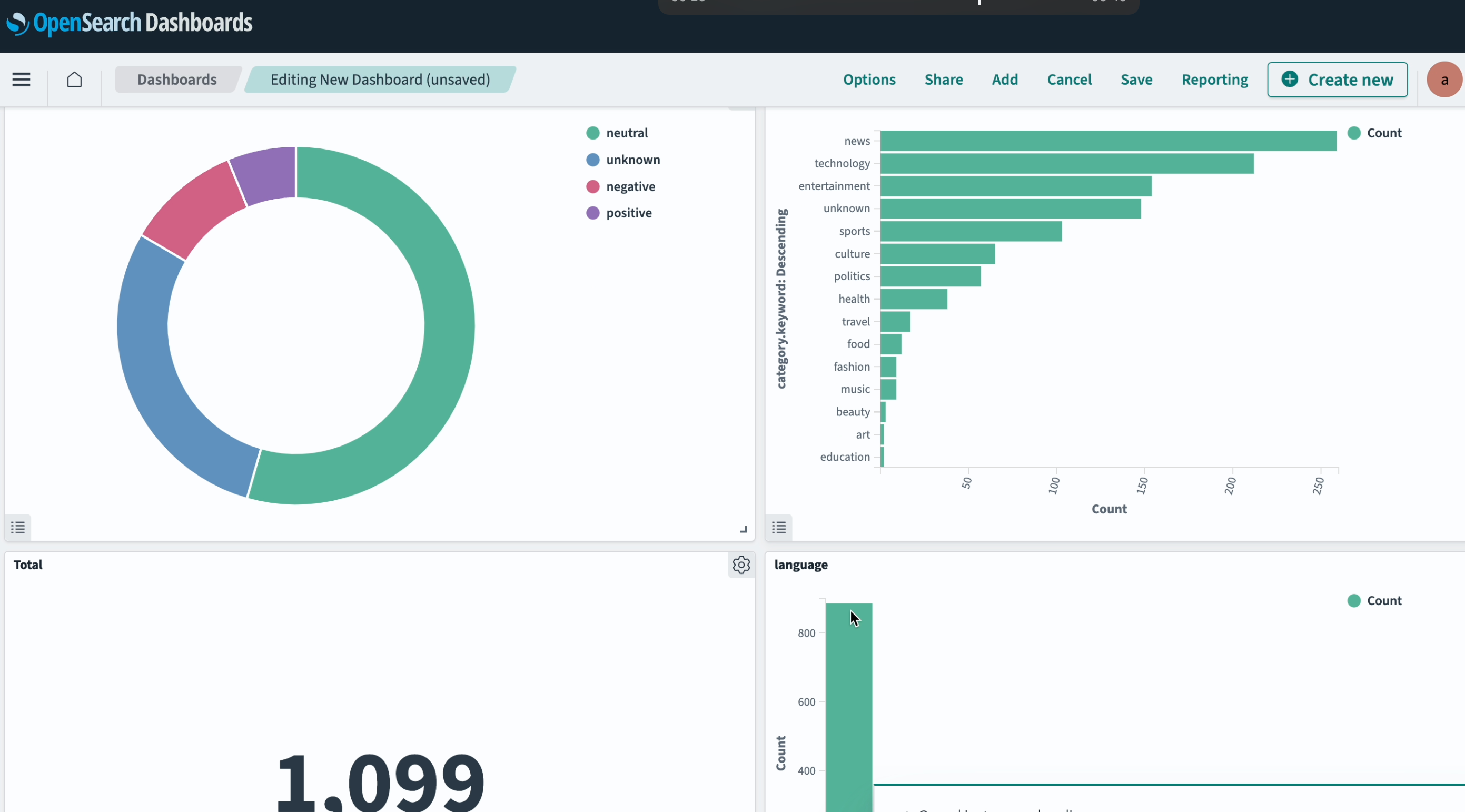
To make it easy to visualize these aggregations and correlations, we'll build a dashboard:
What tech will we use?
To stream, process, analyze and visualize the data, we'll use several open-source technologies.
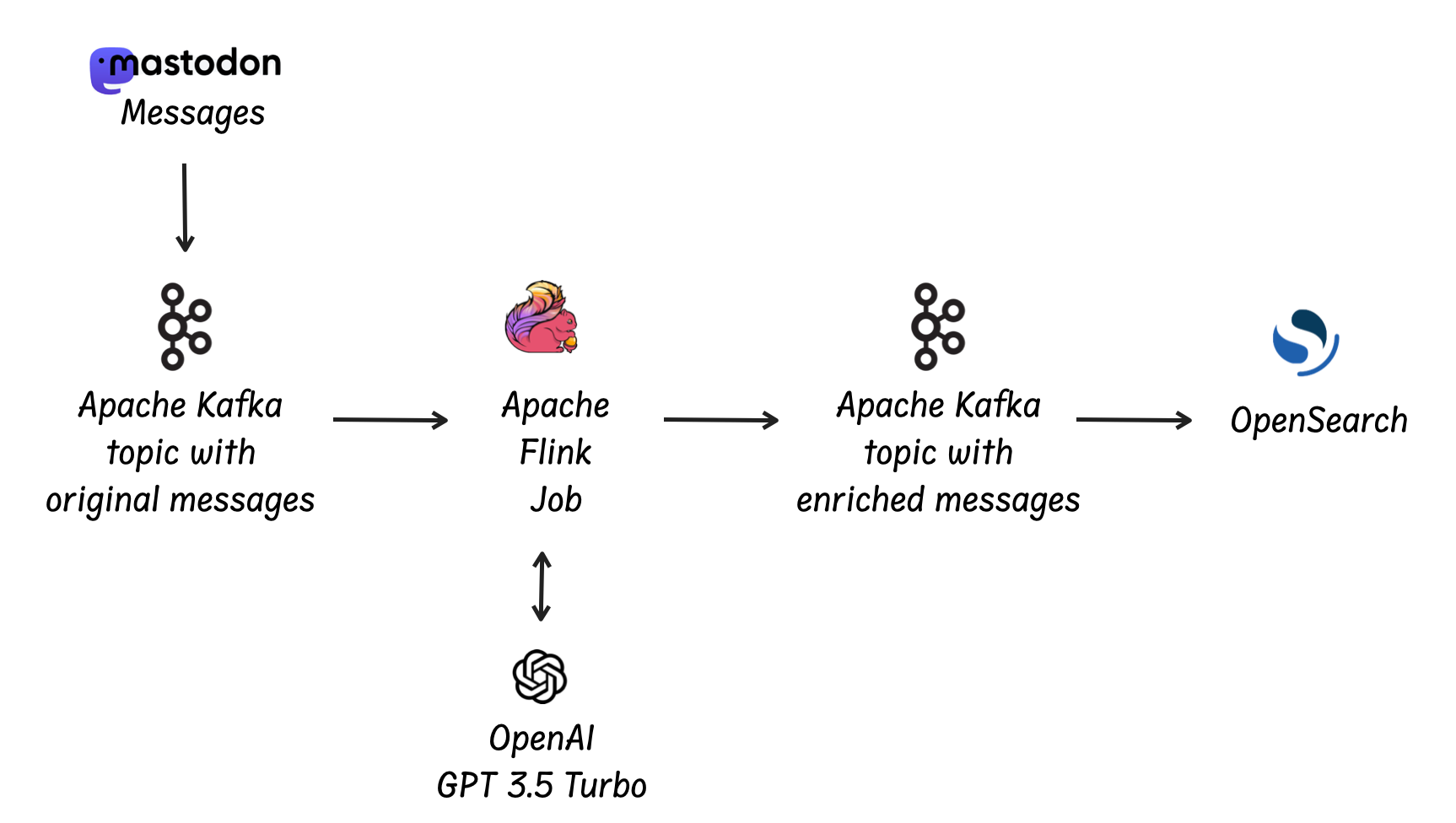
First, we'll use Apache Kafka to handle the real-time data feed from Mastodon. For data processing, we'll rely on Apache Flink, a powerful stream-processing framework. Apache Flink will execute a data flow that sends requests to the OpenAI API to enrich the data. The enriched data will then be streamed into an Apache Kafka topic. Finally, we'll visualize the outcomes using OpenSearch®.
Overall, our data pipeline will look like this:
Let's roll up our sleeves and dive in!
Setting up services
In this tutorial, we'll use the Aiven platform to simplify cloud data infrastructure management and integrations across the data services.
If you haven't registered with Aiven yet, go ahead and create an account. You'll also get additional credits to start your trial for free.
Once you have an account, start by creating these services:
- Aiven for Apache Kafka
- Aiven for OpenSearch
- Aiven for Apache Flink
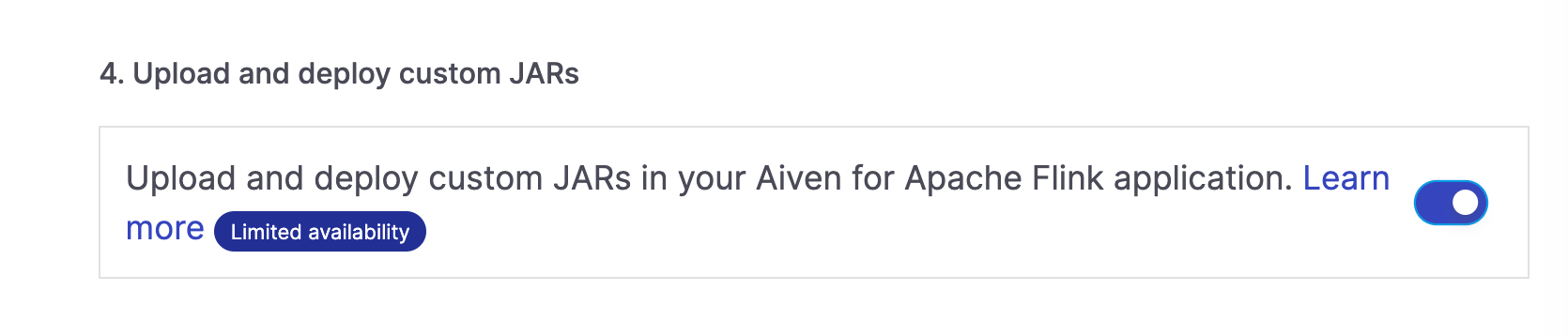
To process data with Flink, we'll use a Java ARchive (JAR). Custom JARs for Aiven for Apache Flink is a limited availability feature, please contact us. Find more in the documentation.
When creating the service, make sure to enable the usage of custom JARs:
Streaming the data into Apache Kafka
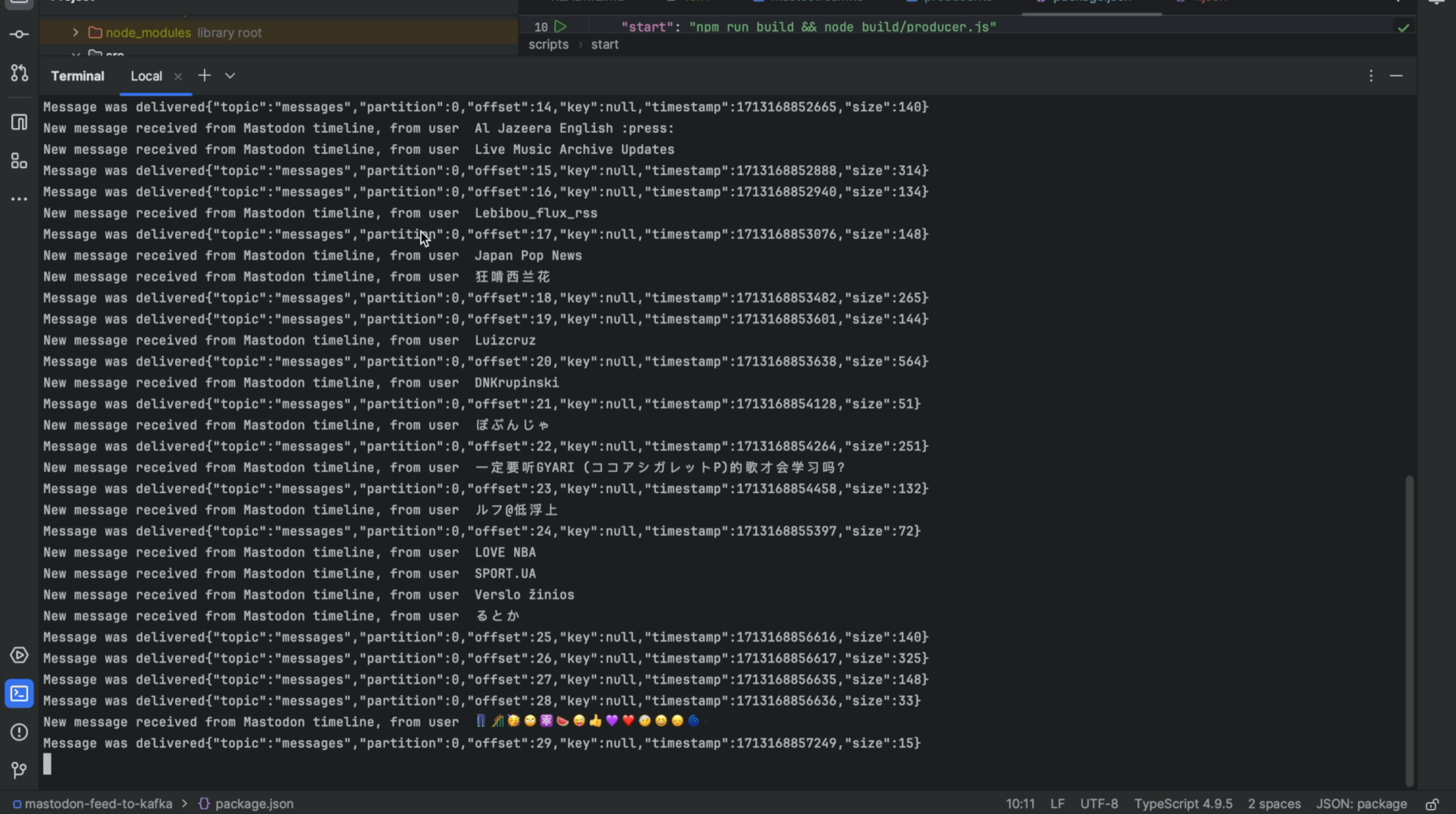
To stream the data from Mastodon to Apache Kafka use this github repository.
By running the Apache Kafka producer code either locally on your laptop or in the cloud (for example, using EC2), the producer will send the public data from https://mastodon.social/public/ to an Apache Kafka topic.
Processing the data with Aiven for Apache Flink and an LLM
Now that the data is flowing into the Apache Kafka topic, it's time to add Apache Flink to our pipeline.
Apache Flink offers a layered API that provides various options for creating a data execution flow. To interact with the OpenAI API, send requests, and process responses, we'll use the Flink DataStream API, which allows us to write the program in Java.
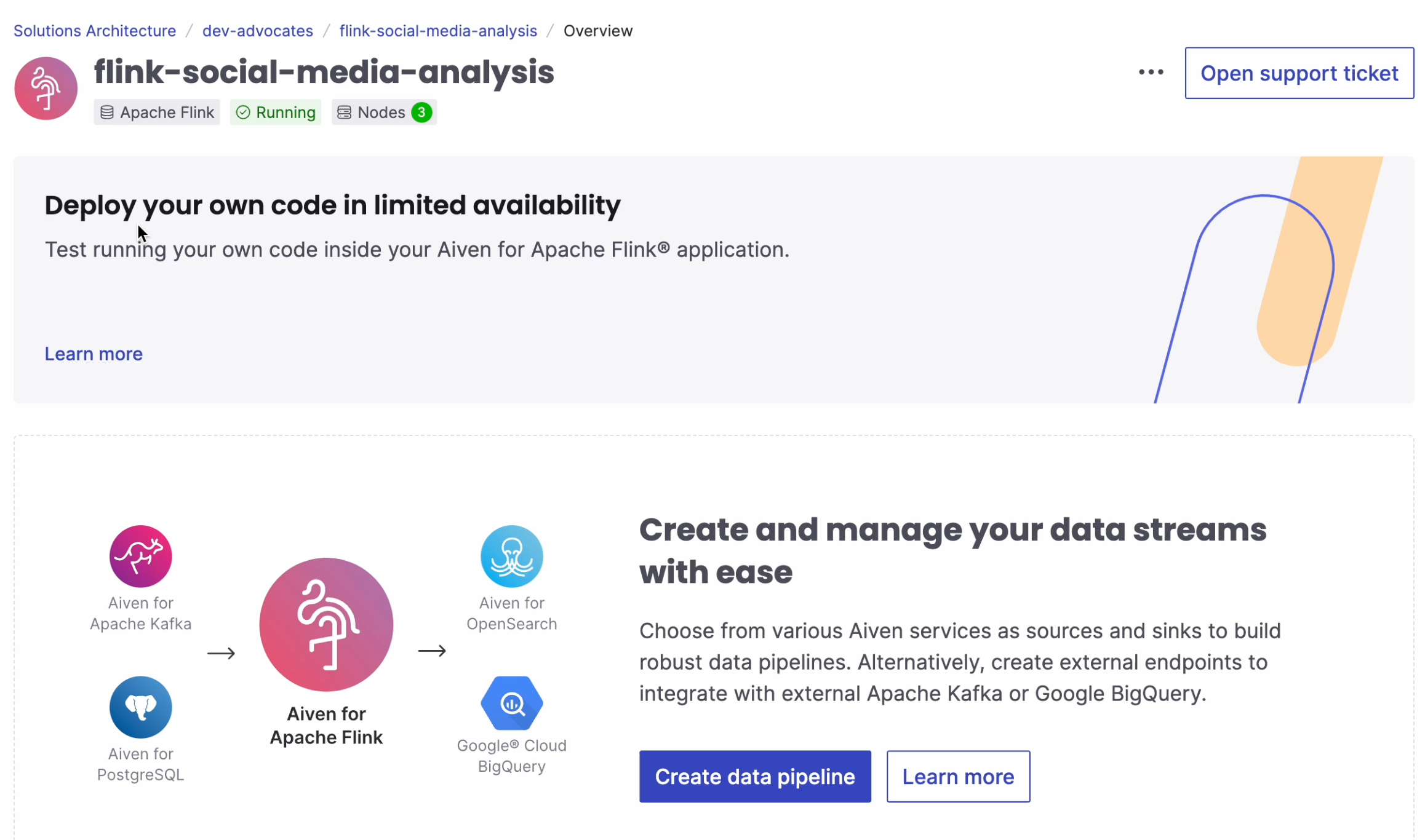
Once you have created the Aiven for Apache Flink service, go to its landing page and click Create data pipeline:

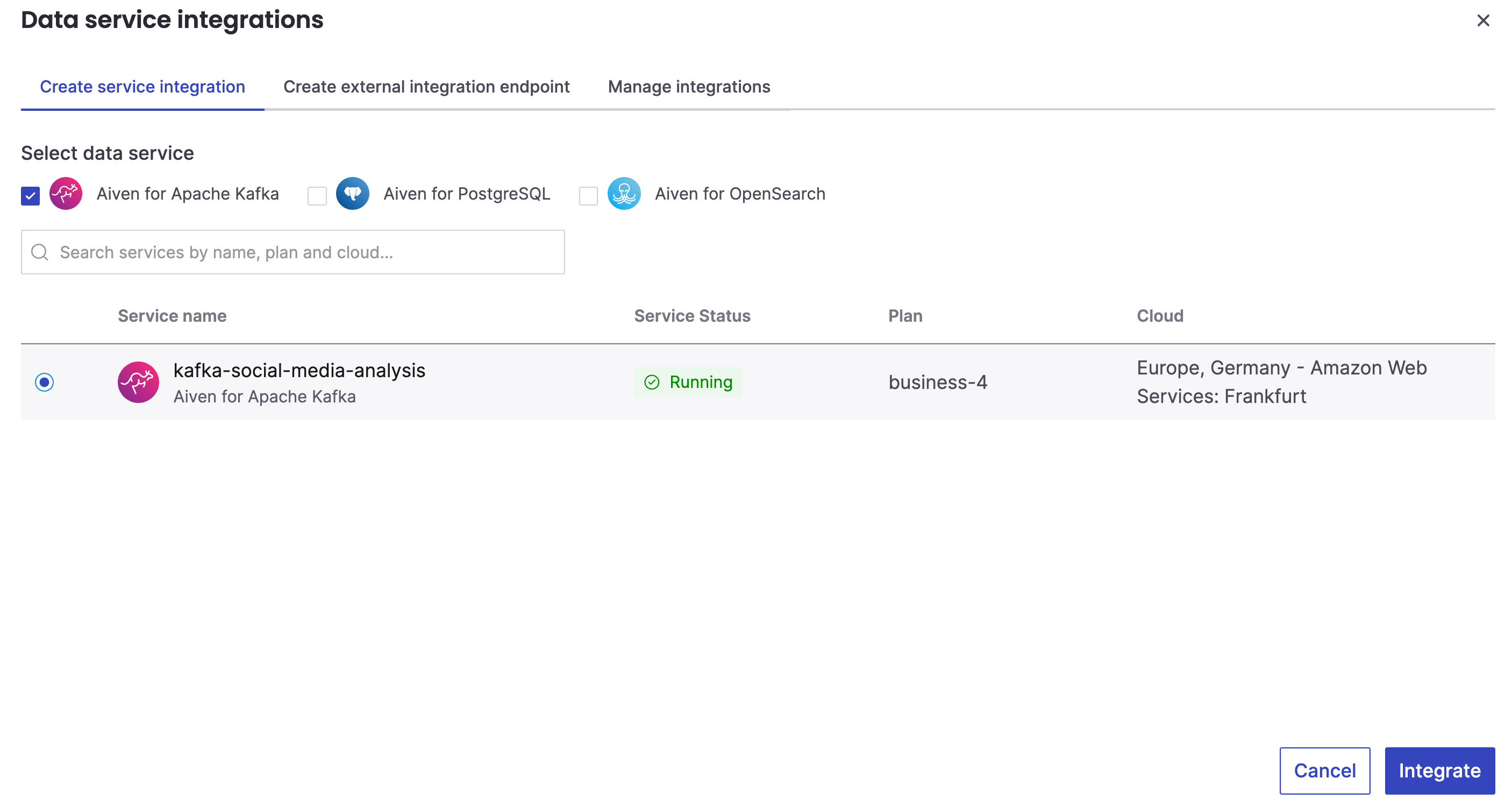
Select your Aiven for Apache Kafka service to connect to:
It's time to create a Flink Java application. Select Applications from the menu and click to create a new application. Choose JAR as the application type.
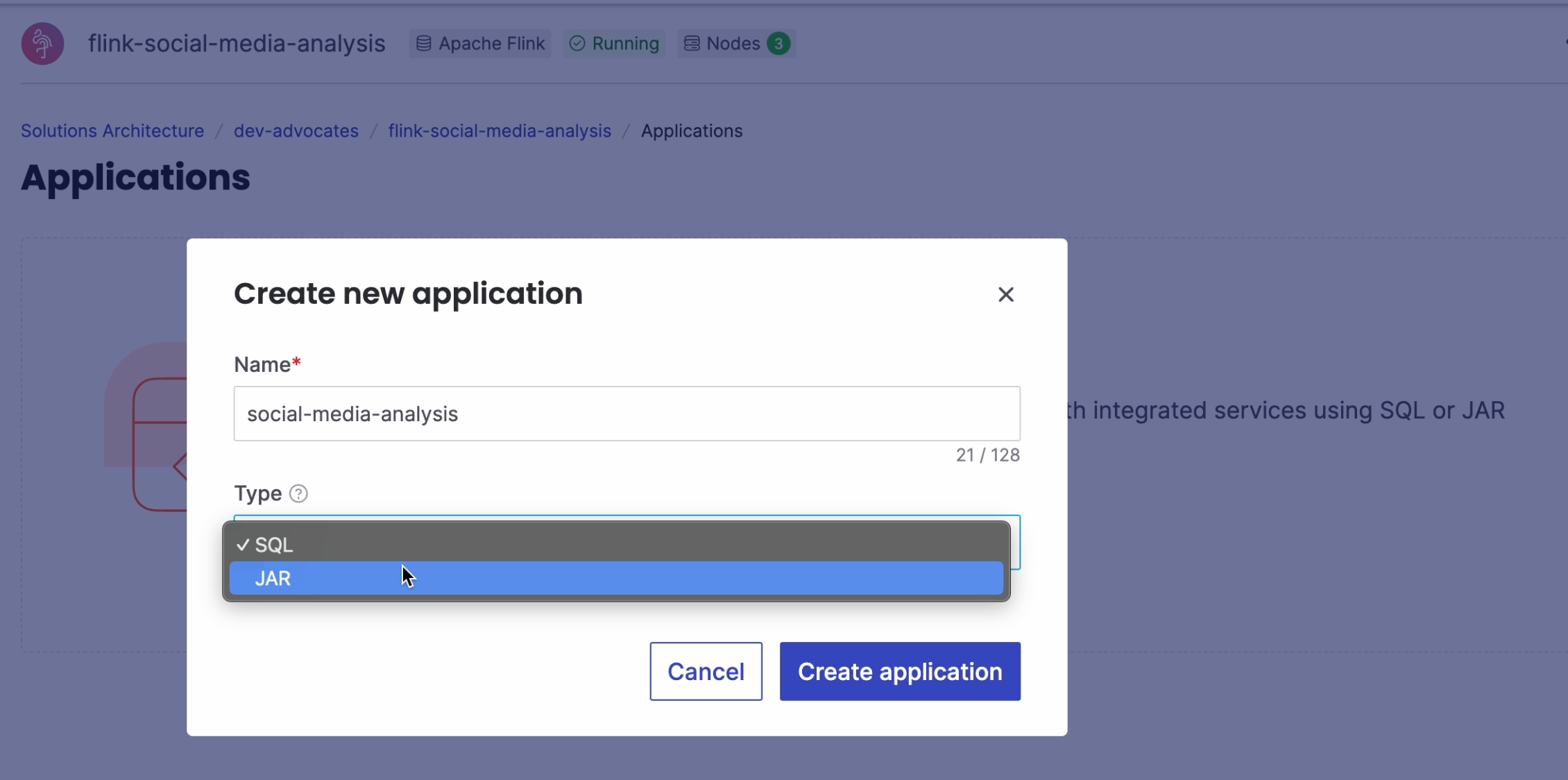
You don't see the JAR option? Make sure you enabled the usage of custom JARs during the service creation.
Navigating Apache Flink logs (optional)
In the following section, we'll be writing an Apache Flink program. Given the complexity, it's common for errors and typos to occur despite our best efforts. This is where logging proves invaluable, serving as a reliable ally during such situations.
You'll be able to access logging directly from the Logs section in your Aiven for Apache Flink service. However, for better convenience, you can also stream the logs into Aiven for OpenSearch (since we already created that service for our visualization, for the sake of this tutorial we can also reuse it for logs).
To send the logs into Aiven for OpenSearch, click "Enable log integration" and select your OpenSearch service.
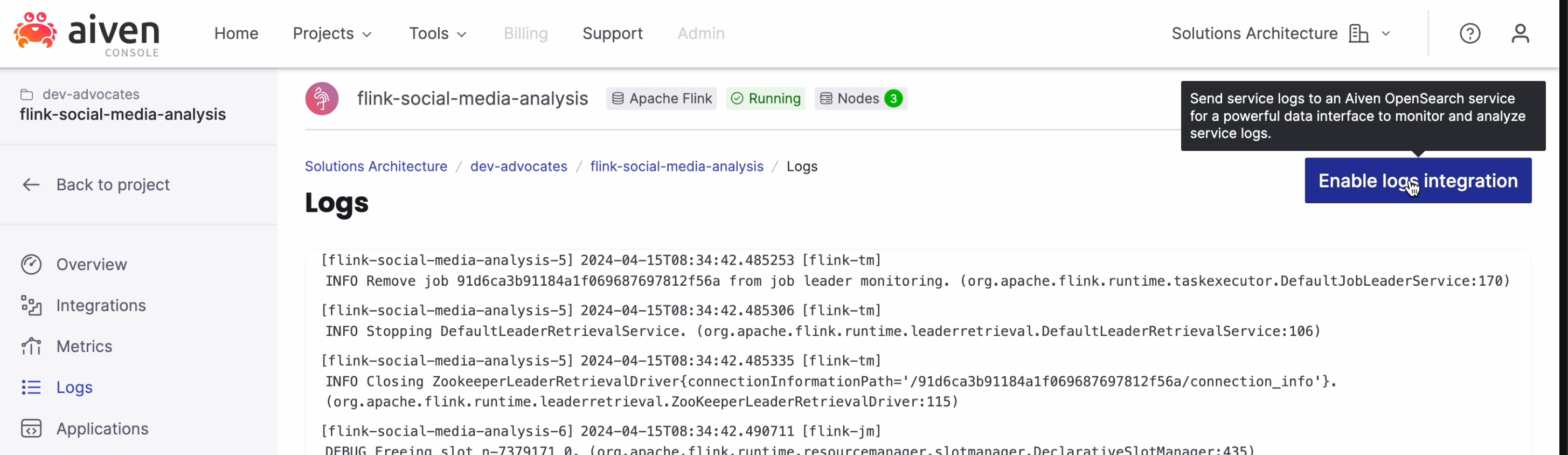
Now you can navigate to the dashboard of your OpenSearch service (here you find more how to start using OpenSearch dashboards), where you can search, aggregate, filter by time, and perform other convenient operations with logs. For example, below is when I searched for specific payloads that were sent to OpenAI while debugging stubborn errors from OpenAI APIs. This capability can be incredibly useful for troubleshooting your Apache Flink application.
Creating Apache Flink job
Time to write some code! You're welcome to use the complete code available in the GitHub repository. Below we break down the code into manageable parts to better understand it.
The structure of a Flink program is quite straightforward and consists of several essential elements:
- Creating an execution environment. This is where we establish the environment in which our Flink job will run.
- Defining the data source. Specify where our program will get its data from.
- Setting the destination for transformed data. We determine where the processed data will be sent after transformations.
- Defining data transformation logic. This is where the magic happens! We instruct Flink on how to manipulate the incoming data to produce the desired output.
- Initiating program execution. Finally, we set the trigger to start the execution of the program.
Let's break down each of these steps using our social media analysis example to understand the flow better.
Creating an execution environment
When working with the DataStream API, we begin by establishing a streaming environment. This is the foundation for the streaming and processing operations. We create it using the StreamExecutionEnvironment class provided by Apache Flink. This step sets the stage for defining our data sources, specifying transformations, and orchestrating the streaming jobs.
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Using external parameters
Often we might need to inject some of the environment parameters during the deployment. For our code example we use a couple of external keys in our Flink code:
- OpenAI key to call OpenAI API,
- Aiven service integration id to get access to Apache Kafka credentials.
We'll see a bit later how to supply these values during the deployment, but for now within the code we presume the existence of these parameters:
ParameterTool parameters = ParameterTool.fromArgs(args); // integration key between Aiven for Apache Flink and Aiven for Apache Kafka String integrationId = parameters.getRequired("integration_id"); // openAIKey String openAIKey = parameters.getRequired("openAIKey");
Integrating the data source
To allow Apache Flink access the records from Apache Kafka we need to provide Apache Kafka credentials. These credentials, typically consisting of authentication details such as bootstrapServers, security protocols, etc. Here is how it is achieved through Aiven platform (read more about Credential management for JAR applications:
String credentialsFilePath = System.getenv("AVN_CREDENTIALS_DIR") + "/" + integrationId +".json"; ObjectMapper objectMapper = new ObjectMapper(); try (FileReader reader = new FileReader(credentialsFilePath)) { JsonNode rootNode = objectMapper.readTree(new File(credentialsFilePath)); String bootstrapServers = rootNode.get("bootstrap_servers").asText(); String securityProtocol = rootNode.get("security_protocol").asText();
Using the provided information about bootstrapServers and securityProtocol, we proceed to create a data source. As our data is in String format, we utilize the StringDeserializer.
It's also important to specify the name of the topic from which our data originates. In my case, the topic name is "messages".
KafkaSource<String> source = KafkaSource.<String>builder() .setProperty("bootstrap.servers", bootstrapServers) .setProperty("security.protocol", securityProtocol) .setDeserializer(KafkaRecordDeserializationSchema.valueOnly(StringDeserializer.class)) .setTopics("messages") .setGroupId("flink-consumer-group") .build();
With this we crate a new data stream within the execution environment or Apache Flink.
// Create Kafka Stream as a source DataStream<String> kafkaStream = env.fromSource(source, WatermarkStrategy.noWatermarks() ,"Kafka Source");
Before specifying transformations for our data stream, let's determine where we want to send the processed data.
Setting the destination for transformed data
Just as we defined the source for our data, we now establish a Kafka sink.
Make sure that you specify correctly the name of the topic where you want to stream the results. Create that topic if necessary.
// Configure Kafka sink to processed-messages topic KafkaSink<String> porocessedSink = KafkaSink.<String>builder() .setProperty("bootstrap.servers", bootstrapServers) .setProperty("security.protocol", securityProtocol) .setRecordSerializer(KafkaRecordSerializationSchema.builder() .setTopic("processed-messages") .setValueSerializationSchema(new SimpleStringSchema()) .build() ) .build();
With both the source and destination established, it's time to define the necessary transformations for our data stream.
Using OpenAI as the analysis engine
There are various powerful models available for data analysis tasks such as sentiment analysis, categorization, and identifying inappropriate language. While we could use specialized models for each task, in this tutorial, we'll experiment using a single model: GPT-3.5 Turbo from OpenAI (you can explore other alternatives as well).
This approach allows us to consolidate multiple requests into one question. However, it also presents a challenge. While responses from specialized models are highly deterministic and have consistent formats (usually providing probabilities as numerical values), working with LLMs like GPT-3.5 Turbo introduces some unpredictability. LLMs tend to generate verbose responses, which can be challenging to parse and align across high volume of requests.
We'll see the implications later when we visualize the results. But for now, let me show a somewhat chaotic prompt that I ended up (after numerous iterations) sending to the OpenAI API. Feel free to improve and modify it:
String userMessage = "Your task is to process a social media message delimited by --- ." + "Process the message and give me this information divided by symbol ; Don't use spaces or other punctuations. Use only this order!" + "First is sentiment analysis. Specify only using one of the words POSITIVE, NEGATIVE, UNKNOWN, NEUTRAL. Spell words correctly. Don't use other words" + "Second, identify the language of the message: EN, RU, FR, UA, etc. Use UpperCase, if cannot define use UNKNOWN. Spell words correctly. " + "Third, is there sarcasm in the message. use only these options: HAS SARCASM, NO SARCASM. If cannot define use UNKNOWN. Don't use other words. Spell words correctly. " + "Fourth, closest category of the message: News, Politics, Entertainment, Sports, Technology, Health, Culture, Travel, Fashion, Beauty, Food. Don't use other words." + "Fifth, if it contains any offensive, rude, inappropriate language, or sex language. Use these words: INAPPROPRIATE, APPROPRIATE. Spell words correctly. " + "For example:" + "- It is amazing my favourite sport team has won!, you should return POSITIVE;EN;NO SARCASM;Sports;APPROPRIATE" + "- I'm so angry about this new law!, you should return NEGATIVE;EN;NO SARCASM;Politics;APPROPRIATE" + "Answer with only a set of words in the right order described above, no additional description. Spell words correctly." + "---" + input + "---";
You might notice that I redundantly request the model to spell words correctly and not to use any alternative phrases. While you might think that the LLM is smart enough to understand this with less explanation, my experience proved it to be the opposite. When processing huge volumes of data, occasionally the model either ignores or forgets part of the prompt, or gets creative and does something that we specifically ask it not to do.
By redundantly specifying our requirements throughout the request, I achieved a bit better consistency (we'll see the results very soon!).
The combined request to OpenAI looks like this:
// Construct the JSON object using Jackson ObjectMapper mapper = new ObjectMapper(); ObjectNode payload = mapper.createObjectNode(); payload.put("model", "gpt-3.5-turbo"); ArrayNode messagesArray = mapper.createArrayNode(); ObjectNode systemMessage = mapper.createObjectNode(); systemMessage.put("role", "system"); systemMessage.put("content", "You are an AI processing social media content. You need to process the messages. You spell English words correctly."); messagesArray.add(systemMessage); ObjectNode userMessageObject = mapper.createObjectNode(); userMessageObject.put("role", "user"); userMessageObject.put("content", userMessage); messagesArray.add(userMessageObject); payload.set("messages", messagesArray); return mapper.writeValueAsString(payload);
You can find to the complete method generatePrompt in AiJob.java )
Next we add a method to parse the enriched section by splitting it into chunks:
public String transform() { ObjectMapper dataMapper = new ObjectMapper(); System.out.println("this.intelligentOutput " + this.intelligentOutput); // Create an empty JSON object ObjectNode result = dataMapper.createObjectNode(); // Add text properties to the JSON object result.put("content", this.content); String[] values = this.intelligentOutput.split(";"); if(values.length == 5) { result.put("sentiment", values[0]); result.put("language", values[1]); result.put("sarcasm", values[2]); result.put("category", values[3]); result.put("appropriate language", values[4]); } return result.toString(); }
The call to OpenAI API is done within AsyncHttpRequestFunction that implements AsyncFunction<String, Message>. See complete implementation at AiJob.java.
Transforming the data
To create a processing stream and call AsyncHttpRequestFunction, we use AsyncDataStream. Here, we specify the source stream, the function to process the records, the timeout, and the capacity.
// call AsyncHttpRequestFunction to process messages DataStream<Message> resultDataStream = AsyncDataStream.unorderedWait(kafkaStream, new AsyncHttpRequestFunction(openAIKey), 10000, TimeUnit.MILLISECONDS, 100);
Next we apply the transformation to each of the records using the transform method and sink the result to the porocessedSink.
// For every processed message call transform function and send data to Kafka sink topic resultDataStream .map(Message::transform) .sinkTo(porocessedSink);
Starting program execution
Once we have described the source, the sink, and the transformations, we can start the data flow.
env.execute("Kafka to Kafka Job");
Creating a deployment
Build your JAR file by running mvn clean package (feel free to clone the complete repository).
In the Flink application click Upload the first version and choose the created JAR file (you can find it in the Target folder next to the code).
Press Create Deployment to open the deployment dialog:
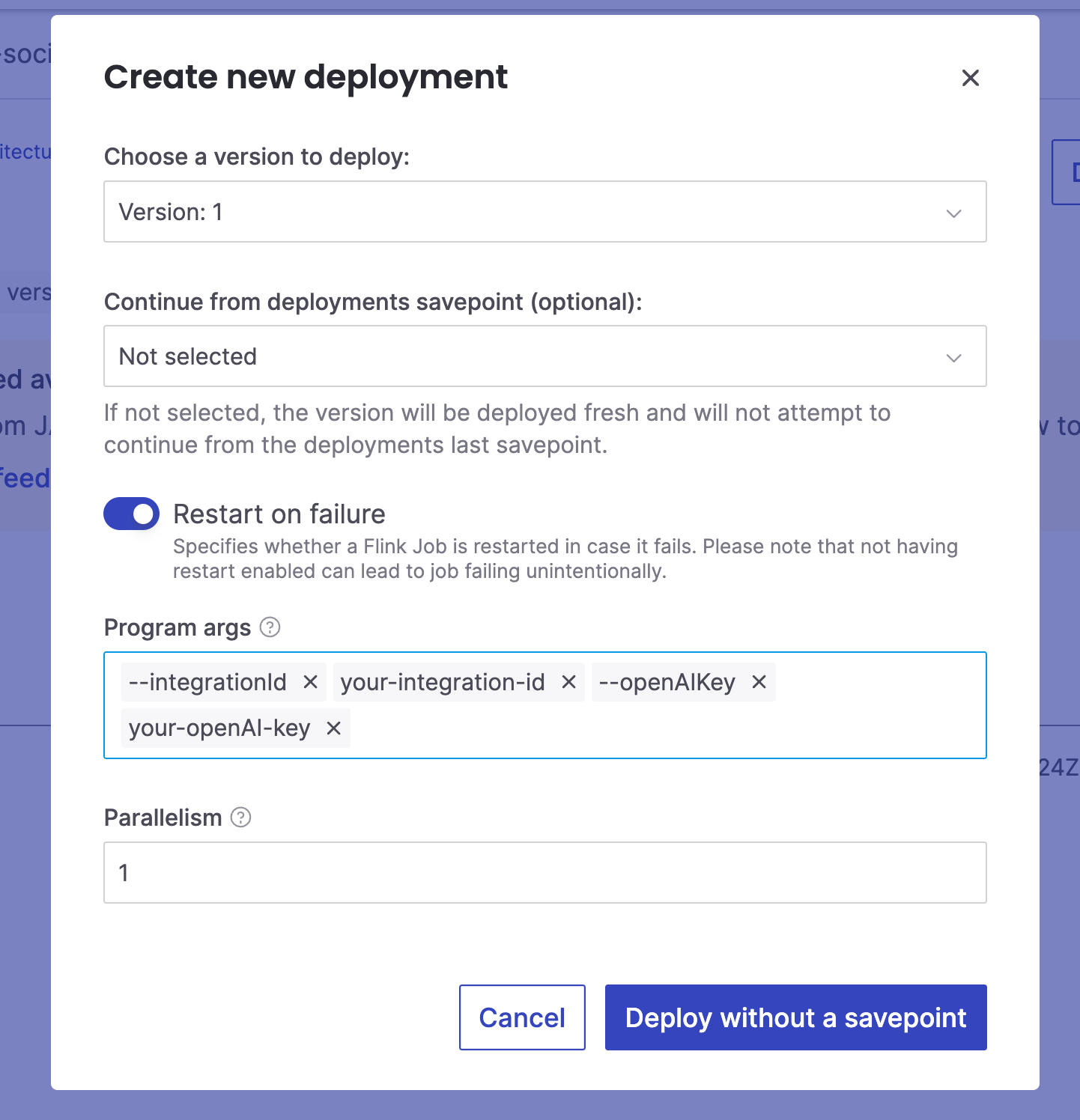
Here you can leave all default parameters with an exception of Program args. In the section Program args we need to enter the parameters that the Java code expects, namely the OpenAI API key and the integration id. Integration id is needed to locate the credentials file. Follow these instructions to get the integration id between your Aiven for Apache Kafka and Aiven for Apache Flink services, look at the usage of this CLI command.
Once the parameters are set in. Click to deploy.
The records will be processed by Apache Flink and sent to the sink topic. Here is an example of a processed record:
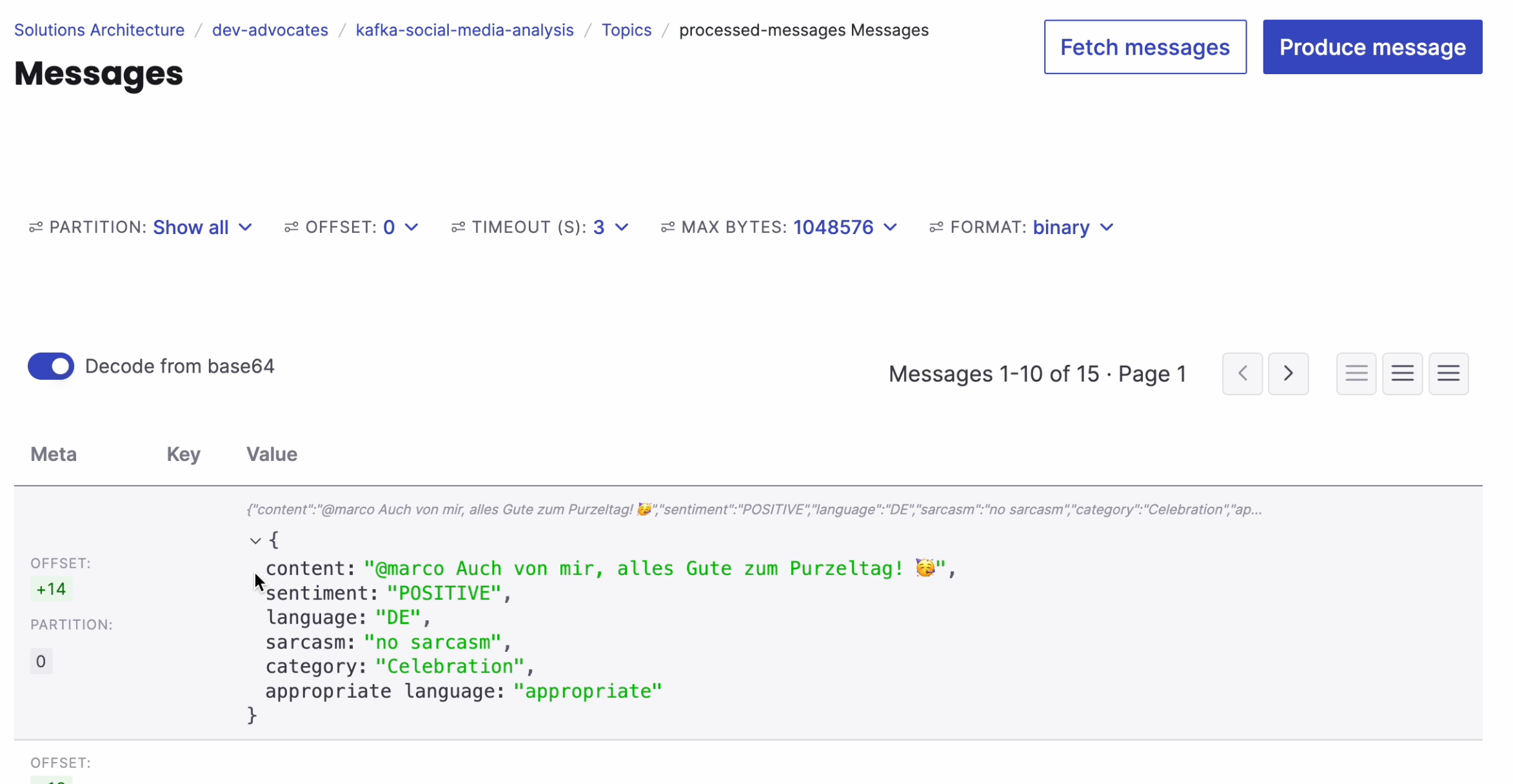
Visualizing
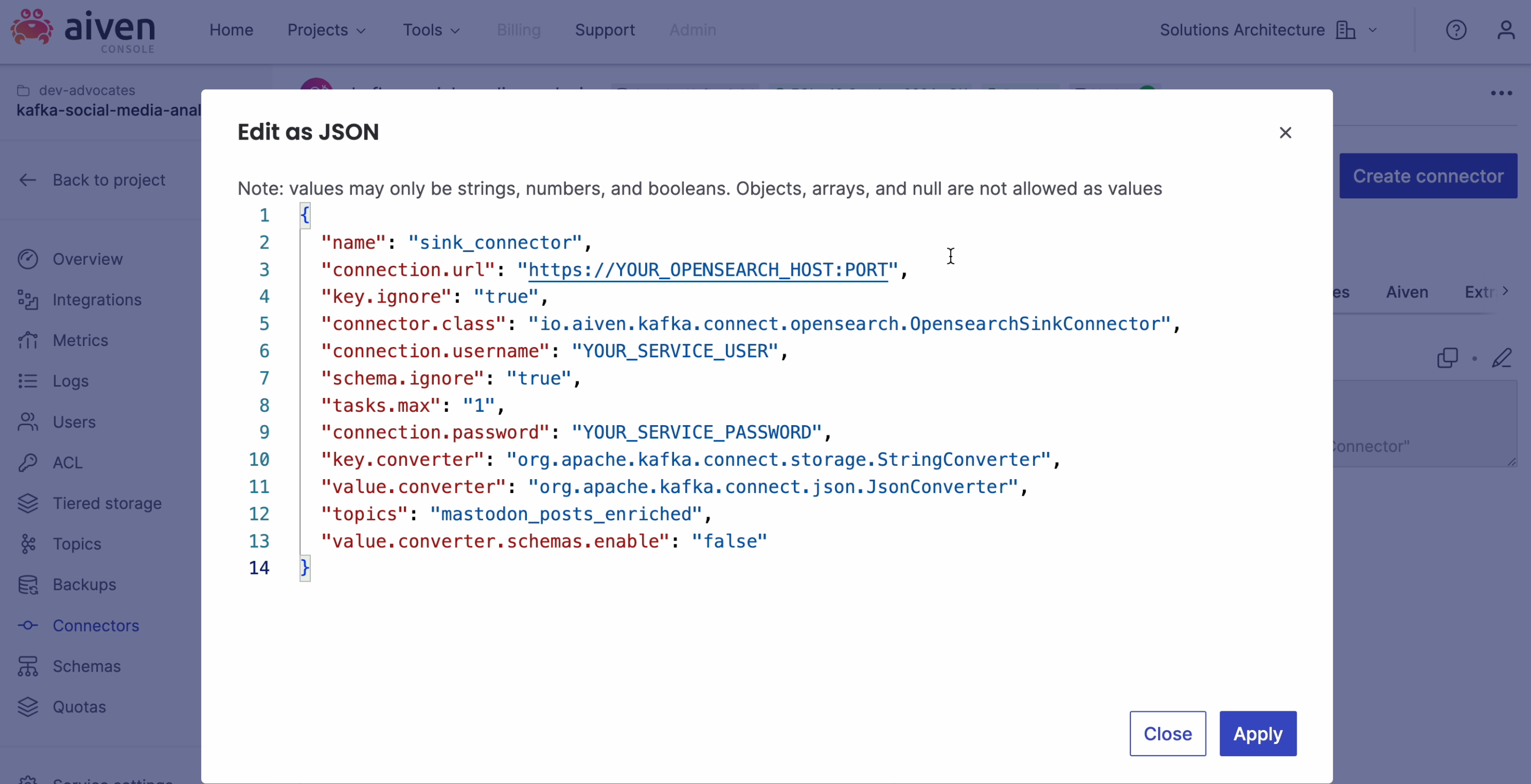
OpenSearch is an excellent tool for visualizing streaming data from an Apache Kafka topic and there is already an Apache Kafka connector available to integrate these two services.
Check for the instructions on how to start using the sink connector. Alternatively look at this tutorial which works with a similar example.
Results and challenges
In the pursuit to optimize the prompt for the LLM, I underwent several iterations. Initially, the GPT model consistently produced misspellings, variations in letter casing, and other orthographic inconsistencies when generating outcomes. Here is a screenshot illustrating these challenges:
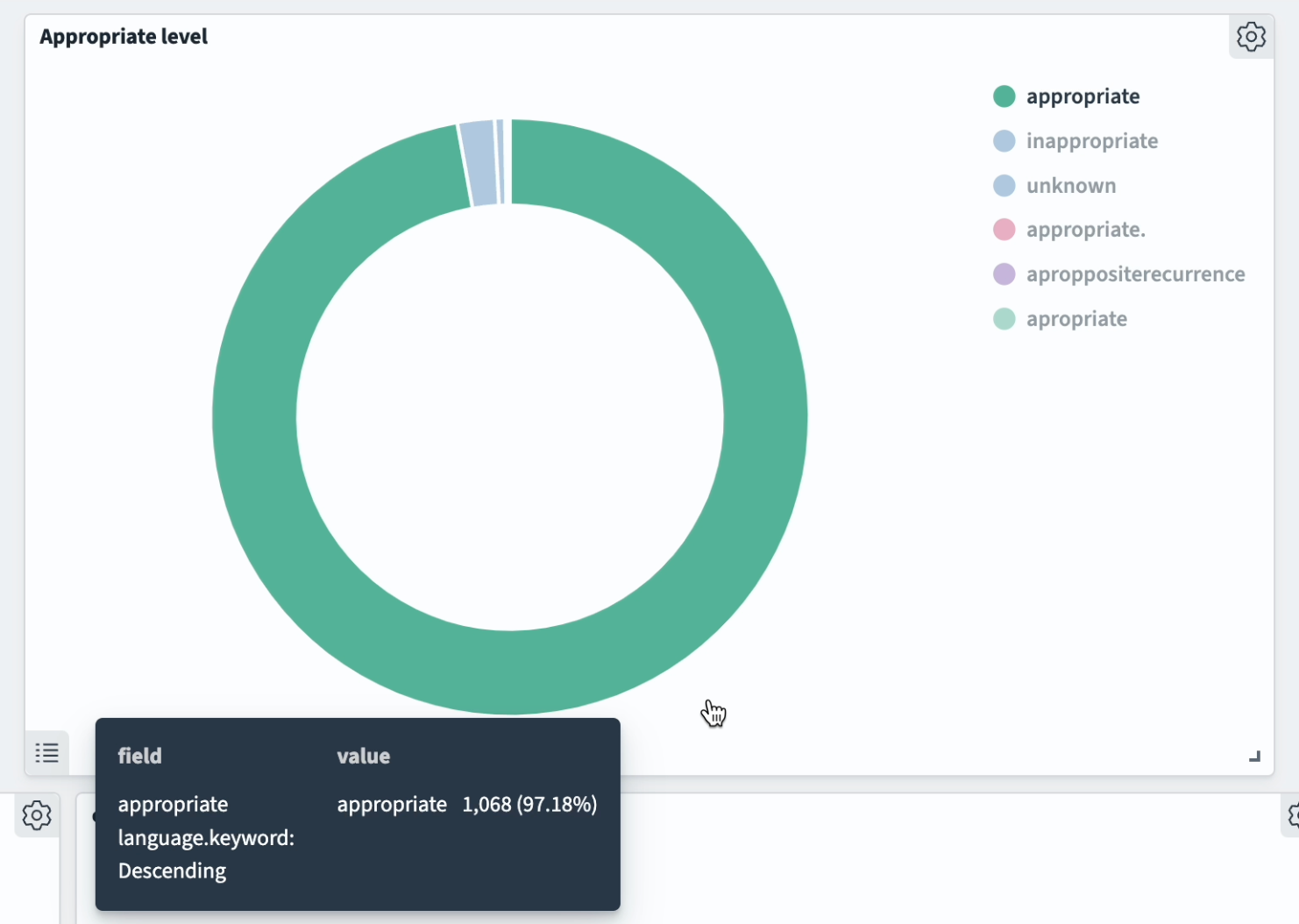
After implementing several iterations, the model outcome improved significantly. However, one persistent challenge remained: marking appropriate language usage. Apparently spelling of the words "appropriate" or "inappropriate" is in the same way challenging for the GPT model, as it is for humans. Notice the misspellings in the screenshot below:
Overall, with the data we've generated, we can now look into various correlations. For instance, we can identify the most significant categories associated with messages of negative sentiment, as illustrated below:
Conversely, the list of categories producing messages with positive sentiment shows interesting distinctions, as well as an overlap with the negative sentiment:

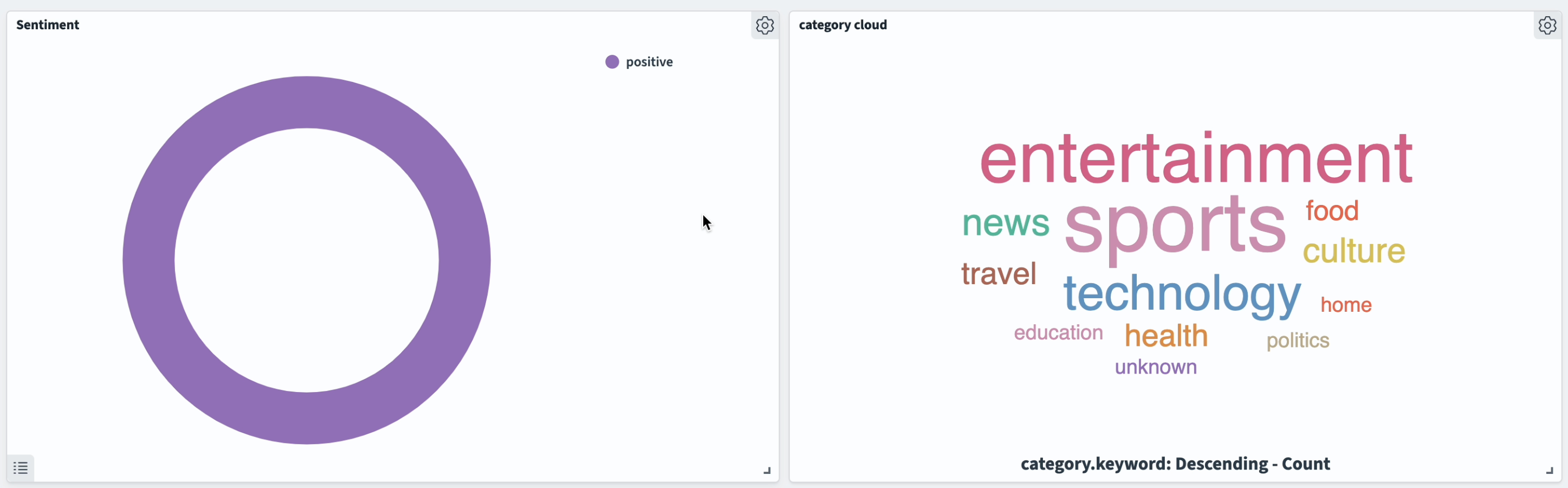
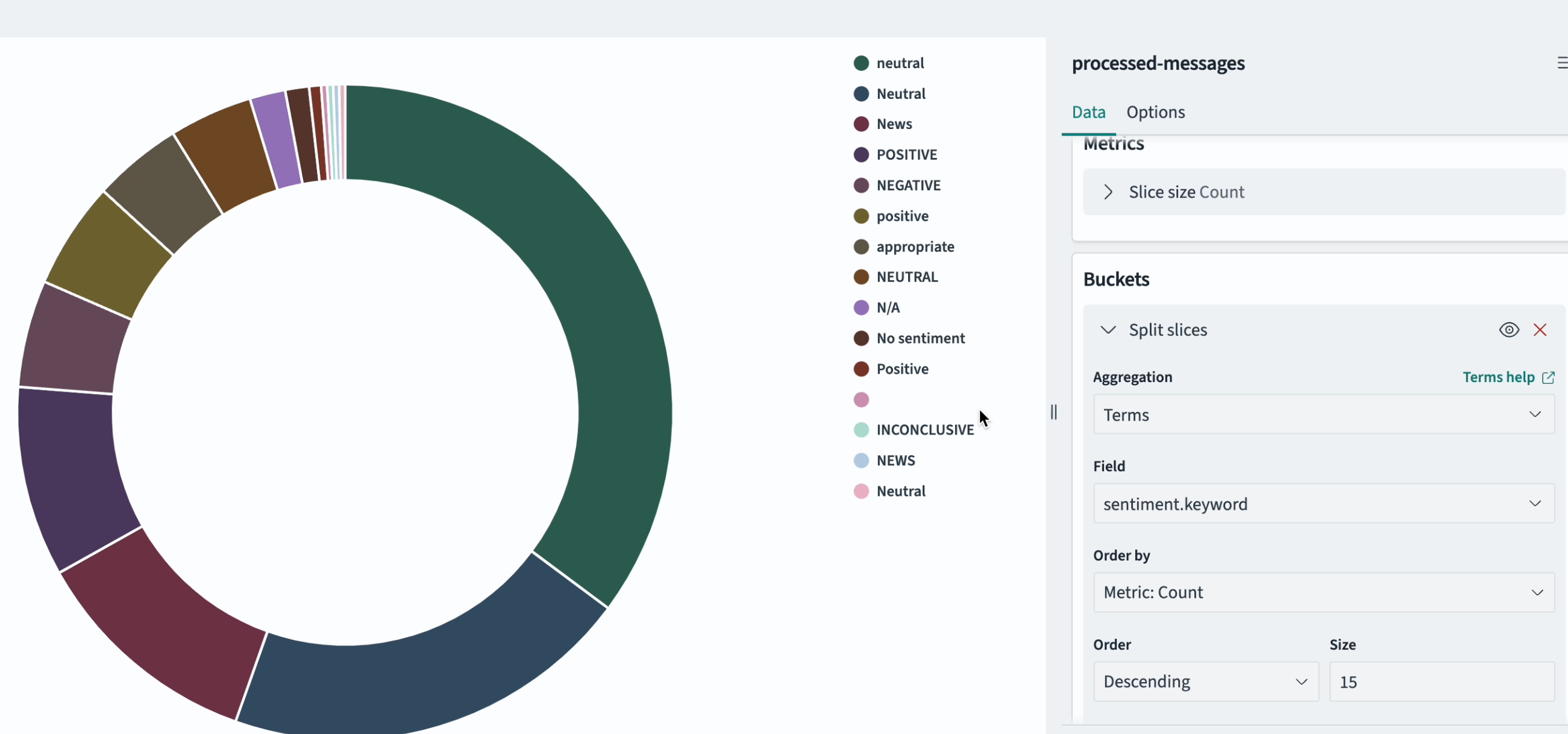
Here is the global distribution of sentiment analysis and the categories:

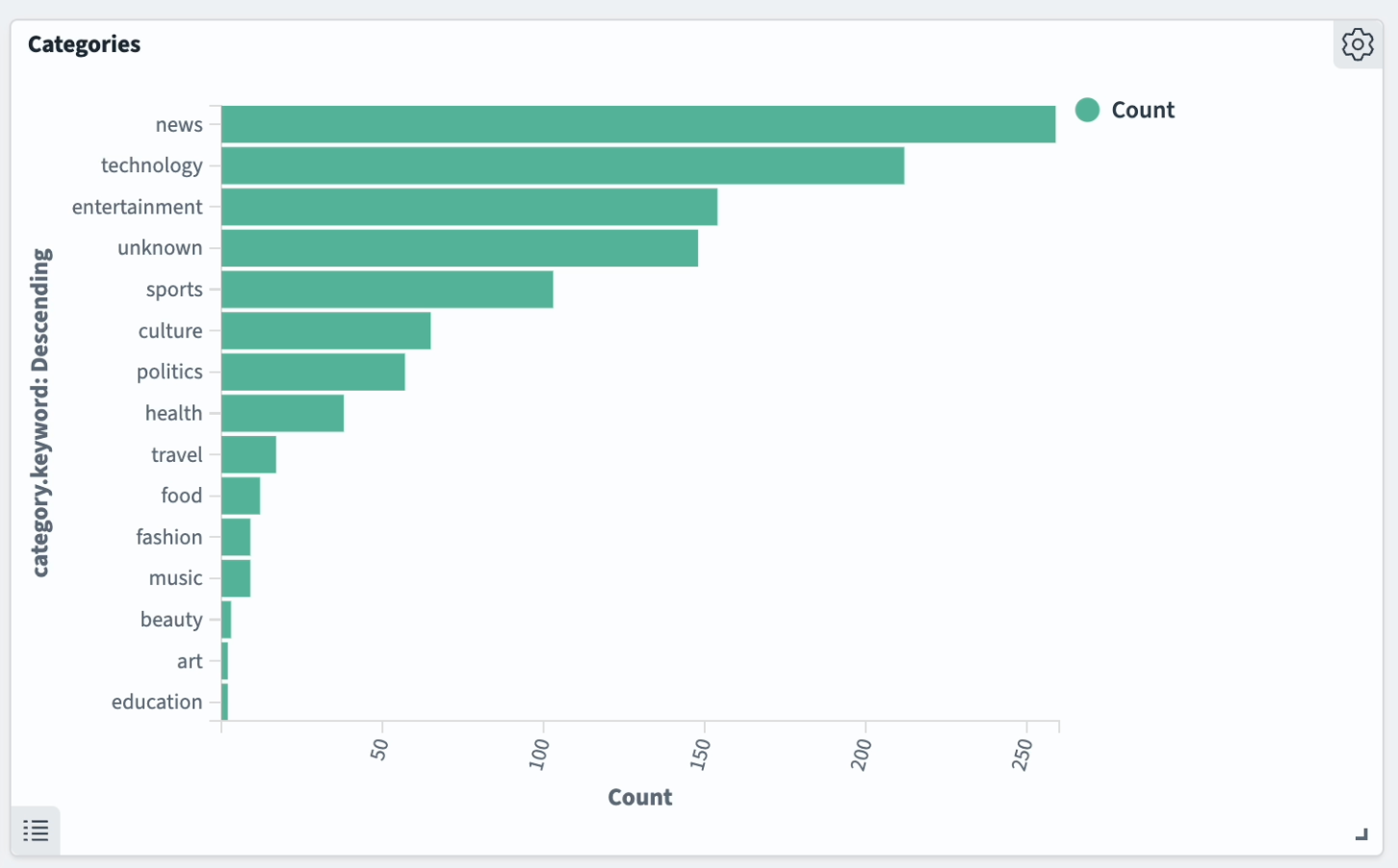
Categories of the messages as defined by LLM:
It's worth noting that the model occasionally diverged from the provided category list, offering its own creative options. Despite this, for the sake of simplicity and efficiency, I opted to proceed without complicating the prompt further.
Conclusion and next steps
In this article, we explored data analysis using OpenAI LLM alongside data streaming technologies like Apache Kafka and Apache Flink. While the usage of an LLM model presents an appealing option for replacing multiple specialized models, unfortunately, its unpredictable behavior adds complexity to writing prompts and parsing responses.
If you're interested in other materials about Apache Kafka and Apache Flink, be sure to check out:
- Apache Kafka® as source and sink with Apache Flink® to process streaming data
- Stream Mastodon data to Apache Kafka® using NodeJS and TypeScript
If you're curious to learn more things you can do with Aiven and AI look at: