Create your own data stream for Apache Kafka® with Python and Faker
How can you test an empty data pipeline? Read on to discover how to create pretend streaming data using Python and Faker.
We've all been there: we installed or purchased a new, shiny data management tool for testing but immediately realized we didn't have any data to use for our trial! We may know the data's schema, but we can't use our company's datasets for a number of reasons.
How can we give the platform a proper try? What if I tell you all you need are a few lines of Python code? We'll use the real-world case of a pizza delivery chain to demonstrate how easy it is to produce proper fake event-based data. The scenario will showcase Faker, a fake data generator for Python, pushing data to Aiven for Apache Kafka using Kafka's SSL authentication.
Watch the video:

Data platforms are empty shells
Databases, data lakes, and datastores in general are cool pieces of technology allowing anyone to manage and analyze data, but they share a common problem: they are completely empty by default. This makes them hard to use for testing, which is still needed to evaluate whether a solution fits your use case.
Several platforms solve this problem by offering pre-filled sample datasets that can be installed or enabled with the help of few commands. Those datasets, however, are pretty static and do not always provide the set of features, fields or cardinality you need to perform your trials.
With Apache Kafka, the scale of this problem is even larger. Not only is it empty by default, but it is also a streaming data platform that works by ingesting, transforming and distributing data on the fly - and it expects a continuous flow of data. Finding streaming data sources is a hard task, and, especially if you just want to test the basics of the platform, setting them up properly can be quite cumbersome.
Creating fake data by hand is also not trivial. Even if you know your data schema, creating a coherent set of rows from scratch is challenging. In this blog post I'll walk you through how to create such a fake dataset for Kafka with a hot topic in mind: Pizza!
Gitpod
This tutorial is also available on Gitpod, which will allow you to avoid a lot of setup and offer an enhanced developer experience.
You have two options :
- Start from scratch and follow along with the tutorial instructions : Start "from scratch" Tutorial
- Start with an almost ready-to-go version where you will still have to provision the Aiven services. Be sure to open
README-gitpod.mdin preview mode to see the instructions : Start "mostly done" Tutorial
1. Kafka setup
Let's start with the tech setup. For this example we'll need a Kafka cluster. Creating it on Aiven.io is really easy:
- Navigate to Aiven.io console and sign in (or sign up; it's quick and easy).
- Click + Create a new service
- Select the Kafka service (if we're picky we can also choose our favorite Apache Kafka version)
- Select the Cloud provider we want to deploy our services to, together with the Cloud region
- Select the service plan based on our needs
- Give the service a name
Since I'm based in Italy I could easily go for the recently created aws-eu-south AWS region, located in Milan, to minimize latency. Your choice depends on where you're located or where you plan to provide your services. For our initial test we're ok in using a Startup plan, knowing we can always upgrade (or downgrade) in the future.
Then click on Create Service. It will take a few minutes before our Kafka 3-node cluster shows up in the RUNNING state.
1.1 Getting the service credentials
While we're waiting for the service to be up and running, we can already start preparing for the next step: downloading the certificates required to connect.

We can go to the Overview tab of our Kafka instance in Aiven.io console where we can easily find the Access Key, Access Certificate and CA Certificate. Then download them to our computer creates 3 files:
service.key: the Access Keyservice.cert: the Access Certificateca.pem: the CA Certificate
On the Overview tab, I can also take note of the Service URI (usually in the form <INSTANCE_NAME>-<PROJECT_NAME>.aivencloud.come:<PORT>) that we'll use to correctly point our producer to the Kafka cluster.
1.2 Auto topic creation and enabling Kafka REST APIs
By default, Kafka producers can push data only to pre-created topics. In order to allow topics to be created on the fly while pushing the first record, in this tutorial we'll enable the kafka.auto_create_topics_enable parameter in Aiven.io console Overview tab; scroll down to the Advanced configuration section and then click the + Add configuration option menu.

The last step needed in the configuration is to enable the Kafka REST API (Karapace) in Kafka's console Overview tab, for our cluster. This step is, strictly speaking, not fundamental, but will allow us to check our producer by reviewing the pushed records in Aiven.io console Topics tab.
2. Python client settings
We'll use the kafka-python client to build our producer. All we need to do is install it:
pip install kafka-python
And then set a Producer. Add this code to a new main.py file
import json from kafka import KafkaProducer folderName = "~/kafkaCerts/kafka-pizza/" producer = KafkaProducer( bootstrap_servers="<INSTANCE_NAME>-<PROJECT_NAME>.aivencloud.com:<PORT>", security_protocol="SSL", ssl_cafile=folderName+"ca.pem", ssl_certfile=folderName+"service.cert", ssl_keyfile=folderName+"service.key", value_serializer=lambda v: json.dumps(v).encode('ascii'), key_serializer=lambda v: json.dumps(v).encode('ascii') )
In the sample code we imported the dependencies and set the correct parameters like bootstrap_servers, ssl_cafile, ssl_certfile and ssl_keyfile which refer to the connection URI and the three certificate files mentioned in the section above. Check the full list of available parameters and the various authentication methods to connect to Apache Kafka with Python in the Aiven documentation.
The value_serializer and key_serializer parameters need a separate explanation. Later on, we will produce each record and key in Json format. To push it properly to Kafka we need to transform them to string format and encode. This is exactly what the code lambda v: json.dumps(v).encode('ascii') does.
We are now ready to push our first message to Kafka's test-topic with
producer.send("test-topic", key={"key": 1}, value={"message": "hello world"} ) producer.flush()
The flush() command blocks the code from executing until all async messages are sent.
If we did our homework correctly, we can now execute the main.py code with
python main.py
We should be able to see in Aiven.io console, under the Topics tab, the topic correctly being created:

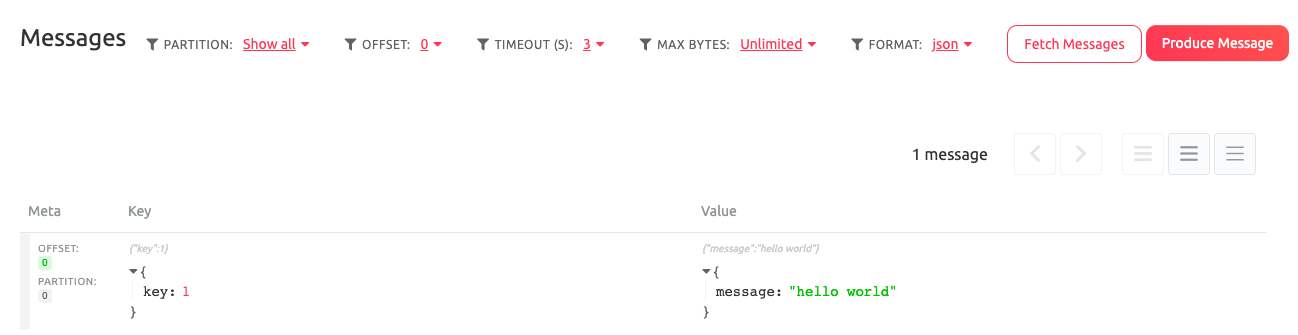
And after clicking on the topic name, on Messages, and selecting json as FORMAT we should be able to view our message:
3. Create Fake Datasets with Faker
So, let's back to our main topic: pizza.
We are the owners of a pizza delivery chain, and of course we want to push our orders to Apache Kafka. We know we receive calls, and note down the client's Name, Address and Phone Number (you never know, we might get lost while delivering). How can we mimic that information?
Welcome to Faker, a Python library allowing us to create proper fake data! We need to be on Python 3.5 and above, and we can install it with
pip install Faker
We just need a simple code to create one (or more) tuple of data containing the Name, Address and Phone Number
from faker import Faker fake = Faker() message= { 'name':fake.name(), 'address':fake.address(), 'phone':fake.phone_number() } print(message)
Which will print a record like the below
{'name': 'Adrian Cole', 'address': '9395 Smith Canyon\nSullivanport, UT 22200', 'phone': '001-959-108-3651'}
We can even localise the output by passing the locale as argument like
fake = Faker('it_IT')
The same example above, localised in Italian with the it_IT parameter will generate
{'name': 'Sig. Leopoldo Piacentini', 'address': 'Piazza Cocci 707 Piano 3\nSesto Isabella lido, 53704 Forlì-Cesena (FE)', 'phone': '+39 12 26548428'}
Perfect, now our basic fake data generator is ready!
Well... a <Name, Address, Phone Number> tuple is not really rocket science, and also doesn't tell us anything about our business. We are a pizzeria, where are the pizzas?
Surprisingly Faker's standard providers do not include a pizza generator, but don't worry, we can create our own.
3.1 Create Custom Data Provider
We know we have a standard pizza menu consisting of few options, ranging from the traditional Margherita to the Mari & Monti mixing seafood and ham. Creating a fake pizza generator is just a matter of returning a random choice between the available options. We can create a new Faker provider in a separate pizzaproducer.py file.
import random from faker.providers import BaseProvider class PizzaProvider(BaseProvider): def pizza_name(self): validPizzaNames= ['Margherita', 'Marinara', 'Diavola', 'Mari & Monti', 'Salami', 'Pepperoni' ] return validPizzaNames[random.randint(0,len(validPizzaNames)-1)]
We can now import the PizzaProvider in our main.py file and run it for 10 samples
from pizzaproducer import PizzaProvider fake.add_provider(PizzaProvider) for i in range(0,10): print(fake.pizza_name())
We correctly obtain
Mari & Monti Salami Marinara Pepperoni Marinara Pepperoni Salami Pepperoni Margherita Pepperoni
But like in any respectable pizzeria, we allow people to add toppings from a list, and similarly to the above, we can define a custom pizza_toppings function. The same goes to record which pizza shop in our chain is receiving the order, which generation is demanded to the pizza_shop function.
The full pizza fake data provider code can be found here, ready for a copy-paste into our pizzaproducer.py file.
3.2 Creating an order
We now have all the building blocks, let's create an order.
For each call, we note down the Name, Address and Phone Number. The customer however can order 1-10 pizzas, and, for each pizza, 0-5 additional toppings. To generate fake orders, can define a function that accepts a randomly generate orderid and returns the order message and related key.
One thing to note: we decided to key our messages with a representation of the shop name in Json format. This will ensure all orders from the same shop to appear in the same pizza-order topic partition, thus making sure that a shop's requests will be executed following the order arrival time.
# creating function to generate the pizza Order def produce_pizza_order (orderid = 1): shop = fake.pizza_shop() # Each Order can have 1-10 pizzas in it pizzas = [] for pizza in range(random.randint(1, MAX_NUMBER_PIZZAS_IN_ORDER)): # Each Pizza can have 0-5 additional toppings on it toppings = [] for topping in range(random.randint(0, MAX_ADDITIONAL_TOPPINGS_IN_PIZZA)): toppings.append(fake.pizza_topping()) pizzas.append({ 'pizzaName': fake.pizza_name(), 'additionalToppings': toppings }) # message composition message = { 'id': orderid, 'shop': shop, 'name': fake.unique.name(), 'phoneNumber': fake.unique.phone_number(), 'address': fake.address(), 'pizzas': pizzas } return message, key
Calling the above code with
produce_pizza_order(704)
Will generate a key like
{ "shop":"Luigis Pizza" }
And a message like
{ "id": 704, "shop": "Luigis Pizza", "name": "Jessica Green", "phoneNumber": "(549)966-3806x9591", "address": "458 Conway Dale Apt. 510\nZacharyborough, TX 48185", "pizzas": [ { "pizzaName": "Mari & Monti", "additionalToppings": [ "banana" ] }, { "pizzaName": "Peperoni", "additionalToppings": [ "ham" ] } ] }
4. Creating a Fake Producer
We described above two lego blocks: Kafka producer settings and fake order generator. What's missing?
We need a continuous stream of events. This we can easily simulate, for 100 messages for example, with a loop:
import time while i < 100: message, key = produce_pizza_order(i) print("Sending: {}".format(message)) # sending the message to Kafka producer.send(topic_name, key=key, value=message) # 2 seconds of sleep time before the next message time.sleep(2) # Force sending of all messages if (i % 100) == 0: producer.flush() i=i+1 producer.flush()
5. The code is yours!
By following the above steps you should be able to correctly produce events to Kafka. But, if you are keen on looking at the ready-made project, check out the related Github repo which will enable you to generate data within minutes.
After executing the code, we can verify that the Producer did its job by going to the Topics tab in Aiven.io console and checking the pizza-orders offset:

And, since we enabled Kafka REST APIs, also by viewing the actual topic content:

Get your first cluster online now
Apache Kafka as a fully managed service, with zero vendor lock-in and a full set of capabilities to build your streaming pipeline.
Get started for freeWrapping up
If you want to explore the benefits of Apache Kafka, then you need a proper streaming dataset. Whether you want a silly pizza use case or to mimic your datasets, Faker can help you by providing a streaming playground.
- What is Apache Kafka
- An introduction to event-driven architecture
- Getting Started with Aiven for Apache Kafka
- Learn about tools for Kafka
- Learn more about Faker
- Learn how to use kcat
- Check out the related repo
Not using Aiven services yet? Sign up now for your free trial at https://console.aiven.io/signup!
In the meantime, make sure you follow our changelog and blog RSS feeds or our LinkedIn and Twitter accounts to stay up-to-date with product and feature-related news.
Table of contents
- Data platforms are empty shells
- Gitpod
- 1. Kafka setup
- 1.1 Getting the service credentials
- 1.2 Auto topic creation and enabling Kafka REST APIs
- 2. Python client settings
- 3. Create Fake Datasets with Faker
- 3.1 Create Custom Data Provider
- 3.2 Creating an order
- 4. Creating a Fake Producer
- 5. The code is yours!
- Wrapping up