A guide to Apache Kafka® tiered storage with Aiven and Terraform
A guide to what tiered storage is, and how you can start using it with Aiven for Apache Kafka® and Terraform. We’ll set up a cluster, load the data and observe the metrics.
The Apache Kafka® 3.6.0 release brings a highly anticipated feature – tiered storage. Although still in early access and accompanied by certain limitations, it marks a significant milestone. You can already experiment with it in non-production workflows to enhance scalability and cost efficiency.
In this article we’ll look at what is tiered storage, how you can start using it with Aiven for Apache Kafka and Terraform. We’ll set up a cluster, load the data and observe the metrics.
What is tiered storage in Apache Kafka
To understand tiered storage in Apache Kafka, we must first look at how Apache Kafka stores data on the disk. Apache Kafka organizes logs for each partition into segments – sequentially written, immutable files. Each segment contains a range of messages.
For the sake of visualization below, let’s say that the first segment created is Segment0, and the latest currently populated with data is Segment N.
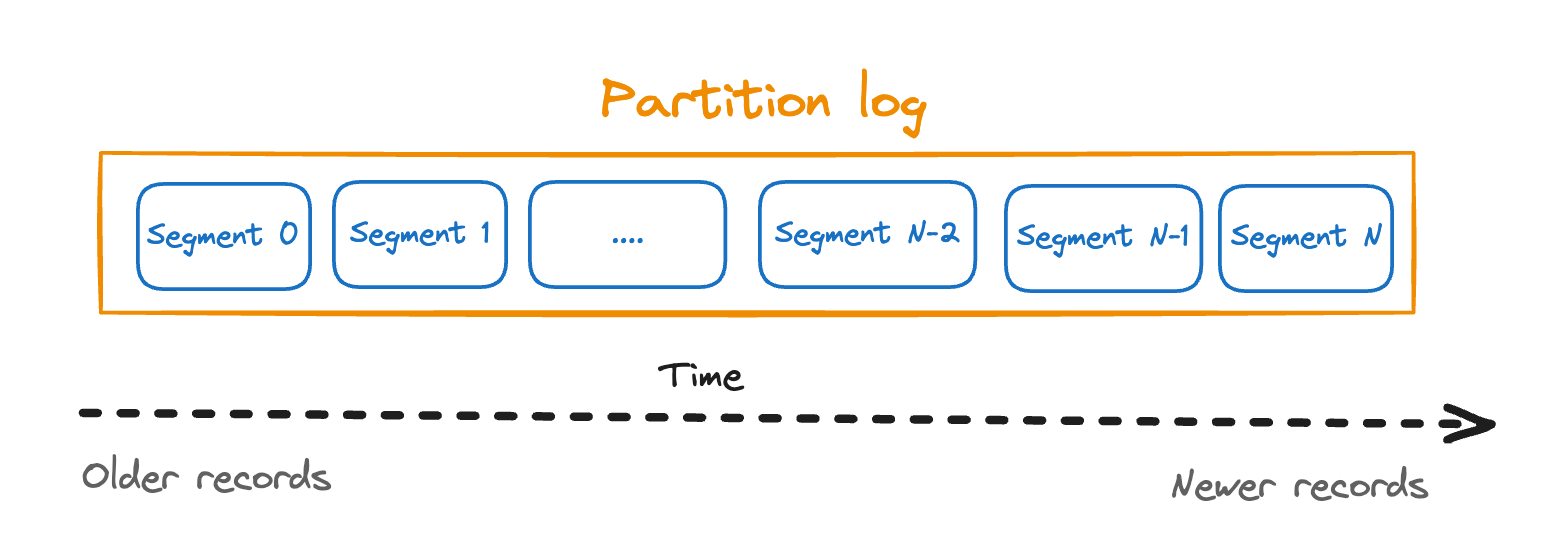
The segment still accepting data writes is considered to be active, in contrast to a “closed” older segment where data is no longer appended.
When we talk about log retention in Apache Kafka, we mean that when the retention limit for a closed segment is exceeded, the segment is deleted.
While this might be a simplified overview, it helps us understand the recent changes added to Kafka's partition architecture to enable tiered storage functionality introduced by the Kafka community.
Apache Kafka's unified log
As part of KIP-405 Apache Kafka was refactored in how it views the log, introducing the concept of a “unified log” that combines the local log (data stored on the broker’s disk), with the remote log (data stored remotely, for example, in an Amazon S3 bucket).
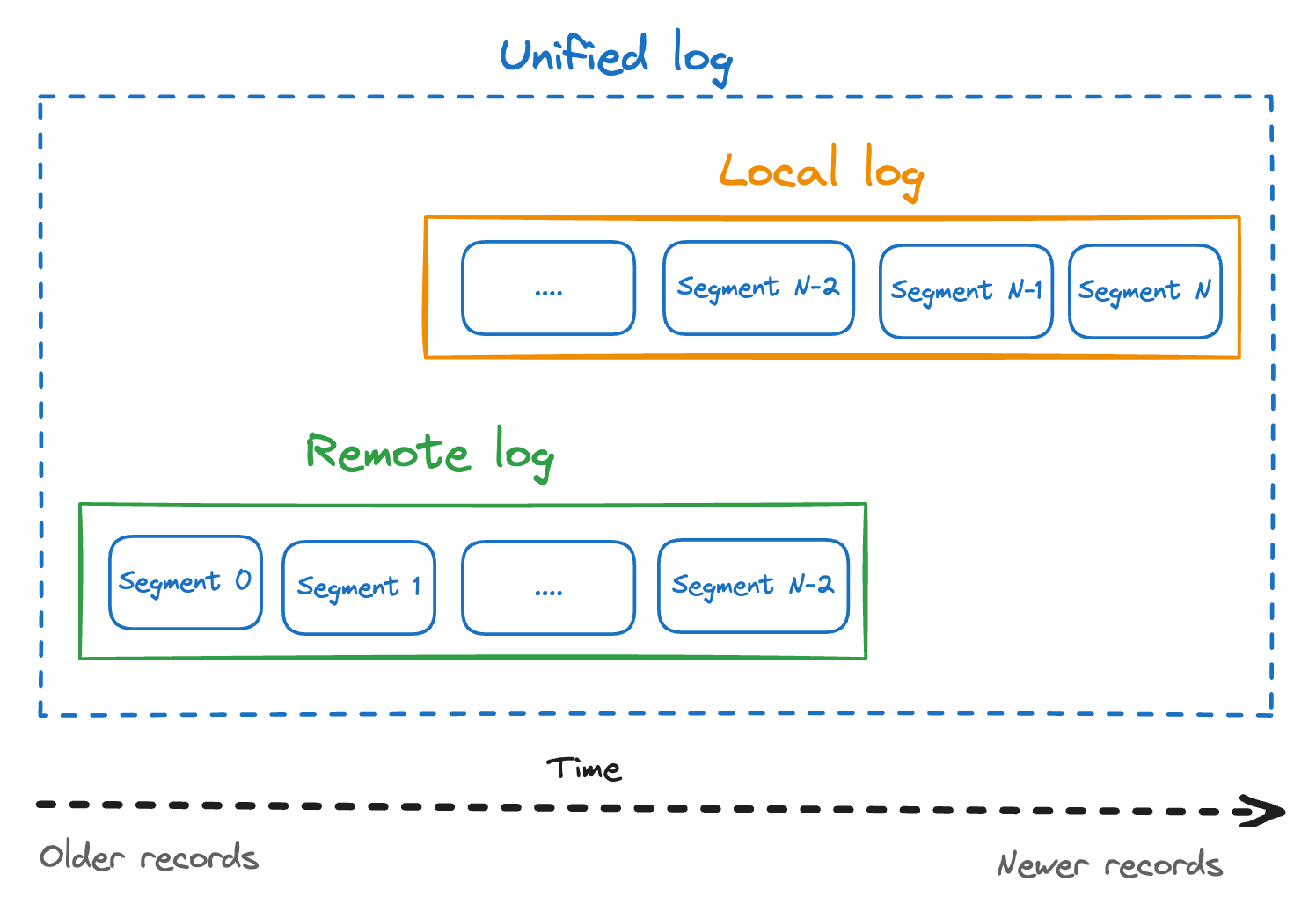
Tiered storage in Apache Kafka means tiering data by retention: older data is moved to remote storage, while recent data stays on the broker. To activate tiered storage for a topic, you'll need to specify the limit for the local retention - either in time or in the amount of bytes. When this limit is reached and data is confirmed to be stored remotely, a local copy is marked to be deleted and the data will then be accessible from the remote storage.
Note that Apache Kafka will try to proactively move any closed segments to the remote storage to ensure that local data can be safely deleted by the time the local retention period is reached. That's the reason for oftentimes having an overlap between logs that have a copy in both the local and remote storage.
Apache Kafka’s pluggable interface for tiered storage
KIP-405 describes the Kafka community's work on incorporating tiered storage into the broker's architecture. However, the broker-side implementation itself is not sufficient for end-to-end use cases. While brokers now include the necessary functionality to schedule jobs to copy segments to some external storage, delete old segments, and work seamlessly with Kafka's unified log, we still need an extra piece - the integration with external data storage, such as Amazon S3 or Google Cloud Storage to efficiently write and consume data. Taking into account the variety of external storages and specific workflows, Apache Kafka provides a pluggable interface and leaves the implementation to vendors and the community itself.
Implementing this interface comes with some additional challenges beyond merely calling the S3 API and shipping data. You see, the segments that we talked about can be huge - Gigabytes in size. Most probably you wouldn't want to send and receive such chunks of data over the network. You'd want to at least compress and encrypt each of those segments, and maybe even divide the segments into smaller chunks that are faster to write and read from the remote storage. Although tiered storage was added to Apache Kafka to avoid some bottlenecks, its improper usage can create some new issues that you probably want to avoid.
Aiven's tiered storage plugin
Aiven addresses these challenges by implementing its own tiered storage plugin, which is capable of efficiently chunking, encrypting, compressing, and caching large log segments. The plugin supports various configurable storage backends, such as Amazon S3, Google Cloud Storage, and Azure Blob Storage.
You can use this plugin both by using tiered storage with Aiven for Apache Kafka or applying the plugin to your self-hosted Apache Kafka.
Below we’ll show how to use Aiven for Apache Kafka with Aiven's tiered storage plug-in. To follow along, you'll need to be registered with Aiven to create an Aiven for Apache Kafka service. You can register over here.
Enable tiered storage in Aiven for Apache Kafka
Please note that at the moment of writing this article, tiered storage is still in early availability and therefore is not recommended for production workloads. To activate tiered storage for your account, contact Aiven's sales team at sales@aiven.io. After activation, enable the feature from the feature preview page in your user profile to start using tiered storage.
Terraform script to create Aiven for Apache Kafka with tiered storage enabled
In this section, we show how to create an Aiven for Apache Kafka service and add a topic with enabled tiered storage using Aiven's Provider for Terraform. If you don't have Terraform installed, follow the instructions from the Terraform documentation.
If you're in a rush, you can also check the complete code in the GitHub repository accompanying this article. Otherwise, follow along for the code step by step.
Alternatively, if you're not a big fan of Terraform (I won't tell this to anyone!), check our documentation to see how to enable tiered storage using the Aiven Console or Aiven's CLI.
To follow best practices, we'll split our Terraform script into several files to have a clean separation of concerns:
- A provider - provider.tf,
- List of variables - variables.tf and variables.tfvars,
- Resources necessary to run an Aiven for Apache Kafka service - kafka-resources.tf.
Let's look at them one by one.
Provider
Start by creating provider.tf. This is where we'll define Aiven's Terraform provider and its specific version:
terraform { required_providers { aiven = { source = "aiven/aiven" version = ">= 4.13.1" } } } provider "aiven" { api_token = var.aiven_api_token }
To initialize the provider you'll need a token, for now we've referenced a not yet existing variable, but we'll come back to the creation of the token in the next section.
Variables
To avoid hard-coded credentials(such as API tokens), or to have flexible values (a project name, for example), we'll put those as variables into a separate file variables.tfvars:
aiven_api_token="PUT YOUR OWN TOKEN HERE" project_name="WRITE HERE YOUR PROJECT NAME"
To generate Aiven's API token follow these instructions from Aiven's documentation.
We'll also need to add the definition of these variables so that we can reference them from terraform files. Create variables.tf and add the following:
variable "aiven_api_token" { description = "Aiven API token." type = string } variable "project_name" { description = "Aiven project name" type = string }
With all of this done we can move to the core of our Terraform script and define the resources that we want to create.
Resources
First, we want to create the Aiven for Apache Kafka service itself. We need to specify the project that the service belongs to as well as other basic parameters. Create kafka-resources.tf and add the following::
resource "aiven_kafka" "kafka1" { project = var.project_name cloud_name = "google-europe-west1" plan = "business-4" service_name = "example-kafka-service-with-tiered-storage" kafka_user_config { tiered_storage { enabled = true } kafka_version = "3.6" } }
Note that to enable tiered storage for Aiven for Apache Kafka you need to have the following:
- Apache Kafka version should be at least 3.6.0
- Enabled tiered_storage in kafka_user_config
- A plan that supports tiered storage. Check the available plans over here
Next, add the resources for a topic:
# Topic for Kafka resource "aiven_kafka_topic" "sample_topic" { project = var.project_name service_name = aiven_kafka.kafka1.service_name topic_name = "sample_topic_with_tiered_storage" partitions = 3 replication = 2 config { remote_storage_enable = true local_retention_ms = 300000 # 5 min segment_bytes = 1000000 # 1 Mb } }
Note that for this example we use a very small size of segment_bytes - just 1 Mb(from the default value of 1 Gb). This will speed up closing the segments and moving them to tiered storage. With this setting we can demonstrate tiered storage in action very quickly, however, using such small value segment_bytes is not something to recommend for production systems, because it will cause too many open files and performance issues.
To enable tiered storage for a topic make sure that you:
- enabled remote_storage_enable,
- set a limit to the local retention either by time (local_retention_ms) or by space (local_retention_bytes).
Planning and applying changes
We're ready to run the terraform script! First we need to run terraform init, then If you want to preview the changes that terraform will do, run
terraform plan -var-file=variables.tfvars
This will allow you to make sure that planned changes is exactly what you expected.
To apply the changes run
terraform apply -var-file=variables.tfvars
Verify the changes and type yes if you want to proceed. It will take some minutes to deploy the service.
And that's it! Once your service is deployed you will be able to use additional tiered storage available for the topic. The data will be gradually moved to the tiered storage. This means that you can store huge volumes of log data over longer periods and have a clear separation between storage and computing. All of this will happen with no changes to the consumer logic.
To observe how data moves to tiered storage, let's load some test data.
Loading data
You can use any test data that you like. I've streamed Mastodon data, you can do that as well, or by using the Sample dataset generator for Aiven for Apache Kafka, or even with kafka-producer-perf-test.sh that is available with any Kafka distribution. The data itself is not that important for us, what we need is enough data, so that we can start seeing it moving to tiered storage.
Important logs and metrics
If you look at the logs of your Aiven for Apache Kafka service, you'll notice log entries indicating that the data is sent to the remote storage:

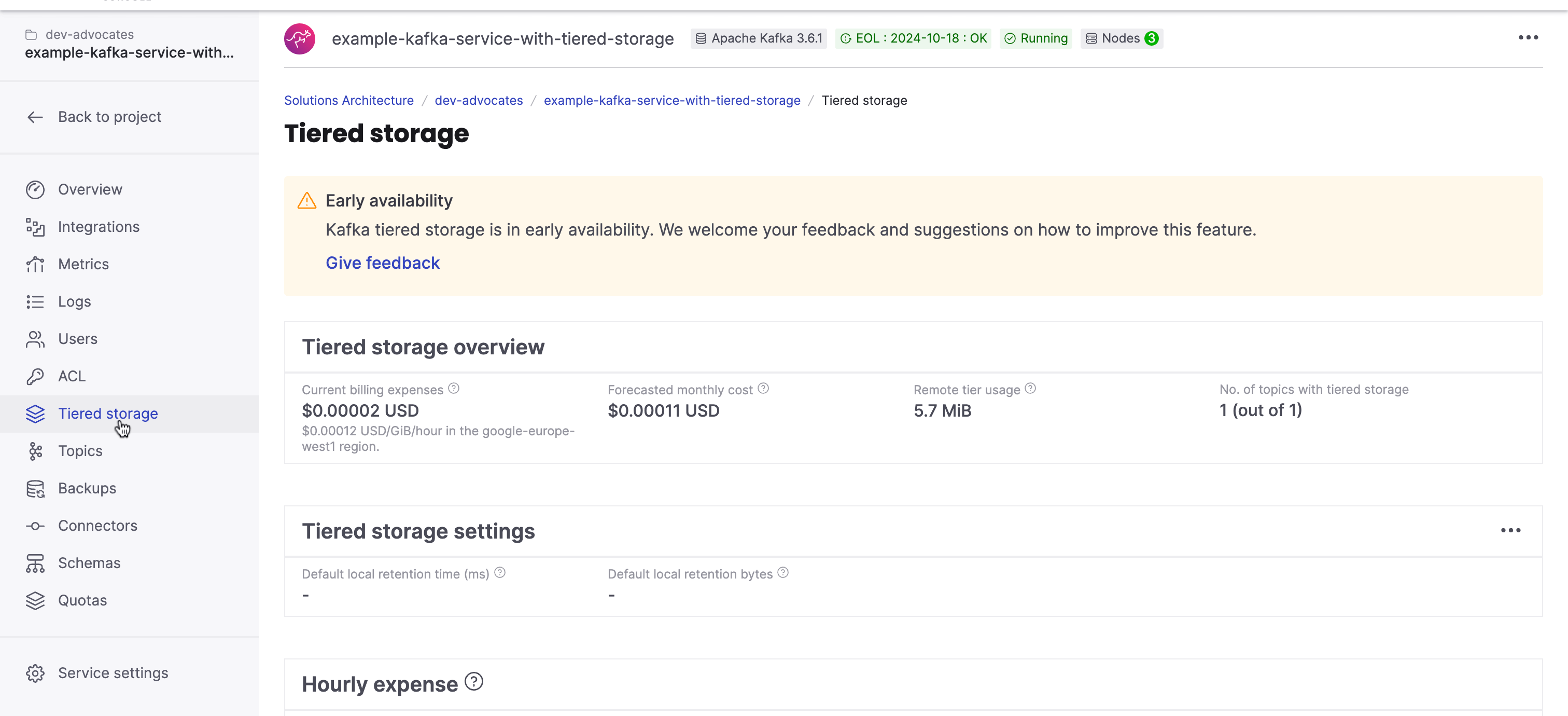
The Aiven Console already visualizes the most important metrics for tiered storage. This is where you can see current billing expenses, forecasted monthly cost, set the remote tier usage, and more:
Cleaning up
Once you're done with this experiment, you can remove the resources create by Terraform by runing
terraform destroy -var-file=variables.tfvars
Wrap up
In this article, we've looked at what is tiered storage in Apache Kafka and how you can start using it already today with Aiven and Terraform.
Learn more about tiered storage and how to use it with Aiven for Apache Kafka from our documentation:
- Tiered storage overview in Aiven Console
- Tiered storage in Aiven for Apache Kafka® overview
- How tiered storage works in Aiven for Apache Kafka®
If you want to expand your knowledge on Terraform, check out these resources we have:
Table of contents
- What is tiered storage in Apache Kafka
- Apache Kafka's unified log
- Apache Kafka’s pluggable interface for tiered storage
- Aiven's tiered storage plugin
- Enable tiered storage in Aiven for Apache Kafka
- Terraform script to create Aiven for Apache Kafka with tiered storage enabled
- Provider
- Variables
- Resources
- Planning and applying changes
- Loading data
- Important logs and metrics
- Cleaning up
- Wrap up