SQL query optimization: a comprehensive developer's guide
An SQL optimization guide for developers. With best practices, warnings, and pro tips to speed up your SQL query optimization.
Ok you got a database, how do you optimize SQL performances? To answer this question you need a lot of time and effort in order to understand workloads and performance patterns, evaluate degradation and apply corrective measures. However there are standard practices that you can implement to improve performances. This SQL optimization guide will showcase some best practices that apply across almost every database and can be a good starting point to optimize your database workloads.
How to optimize SELECT SQL queries
Optimize SELECT SQL queries by understanding the query execution plan
How
All modern databases, like MySQL and PostgreSQL®, define an optimal query execution plan based on the cardinality of the various tables involved and the auxiliary data structures available like indexes or partitions. Both MySQL and PostgreSQL provide a command called EXPLAIN to show the execution plan of a statement. From the execution plan, you can understand how tables are joined, if an index is used, if a partition is pruned and many other aspects of the query execution that could alter the performance. The query plan gives hints about the cost of each operation and can flag if an index is not being used.
To get the execution plan of a query, prefix the query with EXPLAIN like the following:
EXPLAIN SELECT id FROM orders WHERE order_timestamp between '2024-02-01 00:00:00' and '2024-02-03 00:00:00' OR status = 'NEW';
The database returns the plan showcasing, in this example, the usage of two indexes idx_order_date and idx_order_status and a BitmapOr between the two results.
QUERY PLAN --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Bitmap Heap Scan on orders (cost=687.35..7149.18 rows=60333 width=4) Recheck Cond: (((order_timestamp >= '2024-02-01 00:00:00'::timestamp without time zone) AND (order_timestamp <= '2024-02-03 00:00:00'::timestamp without time zone)) OR (status = 'NEW'::text)) -> BitmapOr (cost=687.35..687.35 rows=60333 width=0) -> Bitmap Index Scan on idx_order_date (cost=0.00..655.75 rows=60333 width=0) Index Cond: ((order_timestamp >= '2024-02-01 00:00:00'::timestamp without time zone) AND (order_timestamp <= '2024-02-03 00:00:00'::timestamp without time zone)) -> Bitmap Index Scan on idx_order_status (cost=0.00..1.43 rows=1 width=0) Index Cond: (status = 'NEW'::text) (7 rows)
Warning
The database optimizer will generate an execution plan based on the cardinality estimates. The closer these estimates are to the data in the table, the better the database will be able to define the optimal plan. A plan can also change over time, therefore, when performance of a query suddenly degrades, a change in the plan could be a possible cause. The plan will also depend on the table and additional supporting structures like indexes being created in the database, in the following section we'll analyze how additional structures can impact the performance.
Golden rule
Spend time understanding the query execution plan to find potential performance bottlenecks. Update the statistics, automatically or manually using the ANALYZE command, to provide the database up-to-date information about the various tables load.
Optimize SELECT SQL queries by using indexes
How
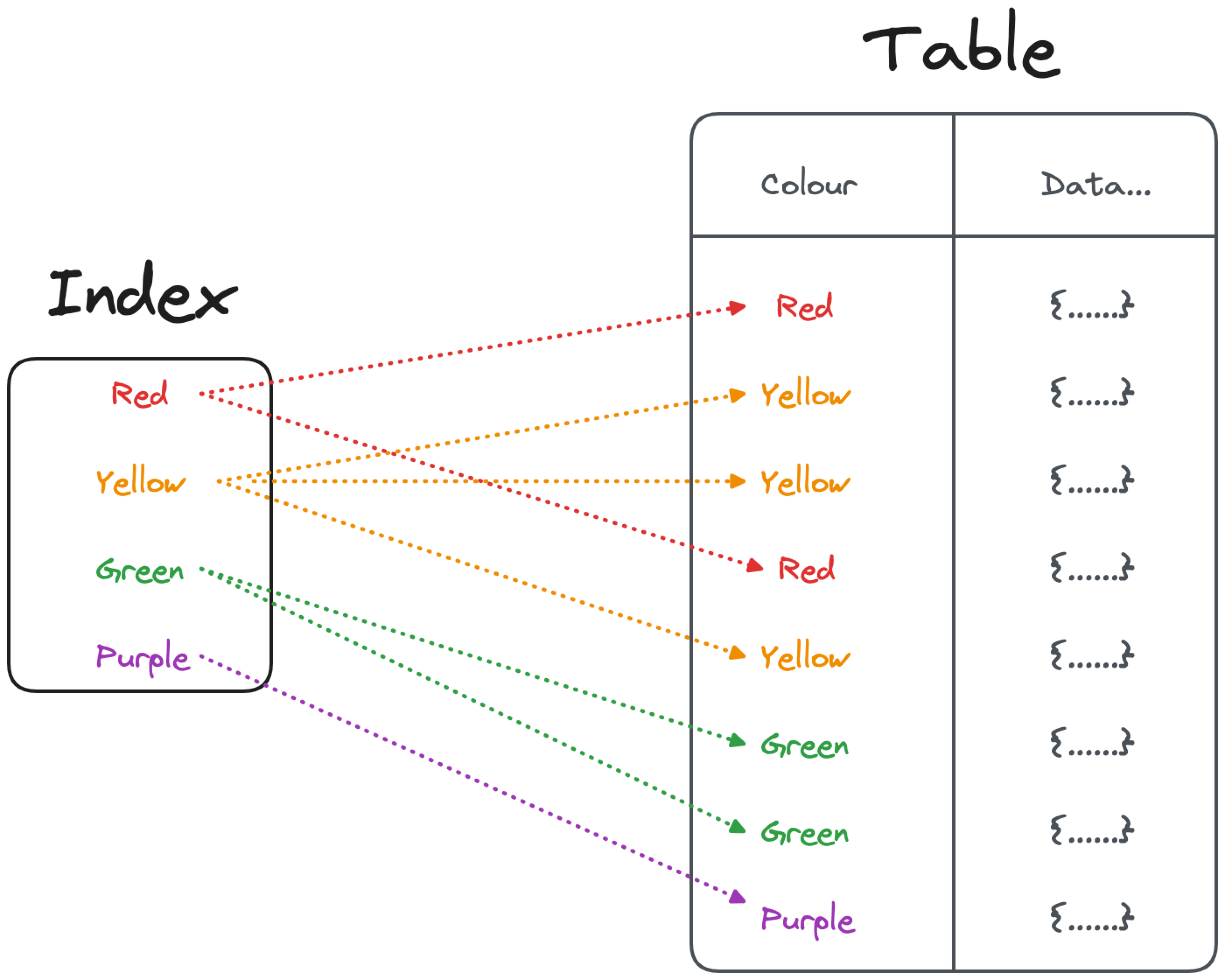
Several of the options defined above suggested the usage of indexes, but how should you use them? Indexes are a key performance booster when performing filtering, joining and ordering. Therefore it’s crucial to understand the query patterns and create proper indexes that cover the correct clauses. Both PostgreSQL and MySQL offer a variety of index types, each one having peculiar characteristics and being well suited for some use-cases.
Warning
As mentioned in the DELETE and INSERT sections, any index added on a table slows down write operations. Moreover, indexes occupy space on disk and require maintenance. Therefore think carefully about which workloads you want to optimize and what is the set of indexes that could give you the best results.
Golden rule
Unlike database tables, indexes can be dropped and recreated without losing data. Therefore it’s important to periodically evaluate the set of indexes and their status. To check indexes usage, you can rely on the database system tables, like PostgreSQL pg_stat_user_indexes or the MySQL table_io_waits_summary_by_index_usage, providing up-to-date statistics about queries impacting the indexes. Once you identify used and unused indexes, evaluate the need of restructuring them in cases of workload change.
Pro tip
Indexes can be used on single columns, multiple columns or even functions. If you’re looking to filter data using, for example, an upper(name) function, you can index the output of the function for better performance.
Aiven AI Database Optimizer can provide you index recommendations based on your database workloads.
Optimize SELECT SQL queries by improving joins
Joins are frequently used in relational databases to select data coming from disparate tables. Understanding what join types are available and what they imply is crucial to achieve optimal performances. The following set of suggestions will help you identify the correct one.
Optimize SELECT SQL queries by selecting inner joins
How
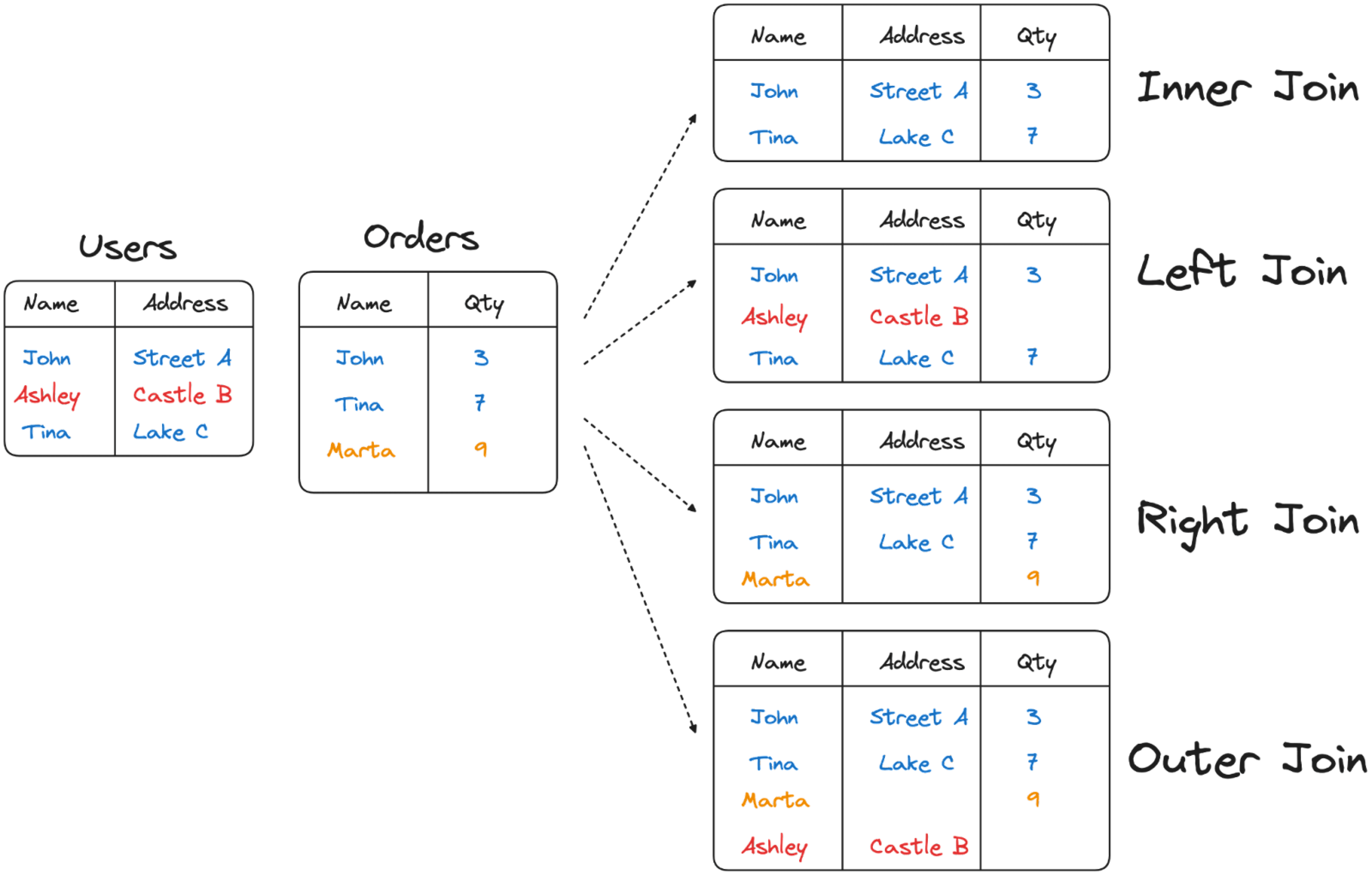
Both MySQL and PostgreSQL offer a variety of join types allowing you to precisely define the set of rows to retrieve from both sides of the join. All of them are useful for one or another reason but not all of them have the same performance. The INNER JOIN retrieving only the rows contained on both sides of the dataset usually has optimal performance. The LEFT, RIGHT, and OUTER joins on the other side, need to perform some additional work compared to the INNER JOIN therefore should be used only if really necessary.
Warning
Double check your queries, sometimes a query like the following seems legit:
SELECT * FROM ORDERS LEFT JOIN USERS ON ORDERS.NAME = USERS.NAME WHERE USERS.NAME IS NOT NULL
The above is using a LEFT JOIN to retrieve all the rows from ORDERS, but then is filtering for rows having USERS.NAME IS NOT NULL. Therefore is equivalent to an INNER JOIN.
Golden rule
Evaluate the exact requirements for the JOIN statement, and analyze the existing WHERE condition. If not strictly necessary, prefer an INNER JOIN.
Pro Tip
Check also if you can avoid a join altogether. If, for example, we are joining the data only to verify the presence of a row in another table, a subquery using EXISTS might be way faster than a join. Check a detailed example in the How to speed up COUNT(DISTINCT) blog.
Optimize SELECT SQL queries by using the same column type for joins
How
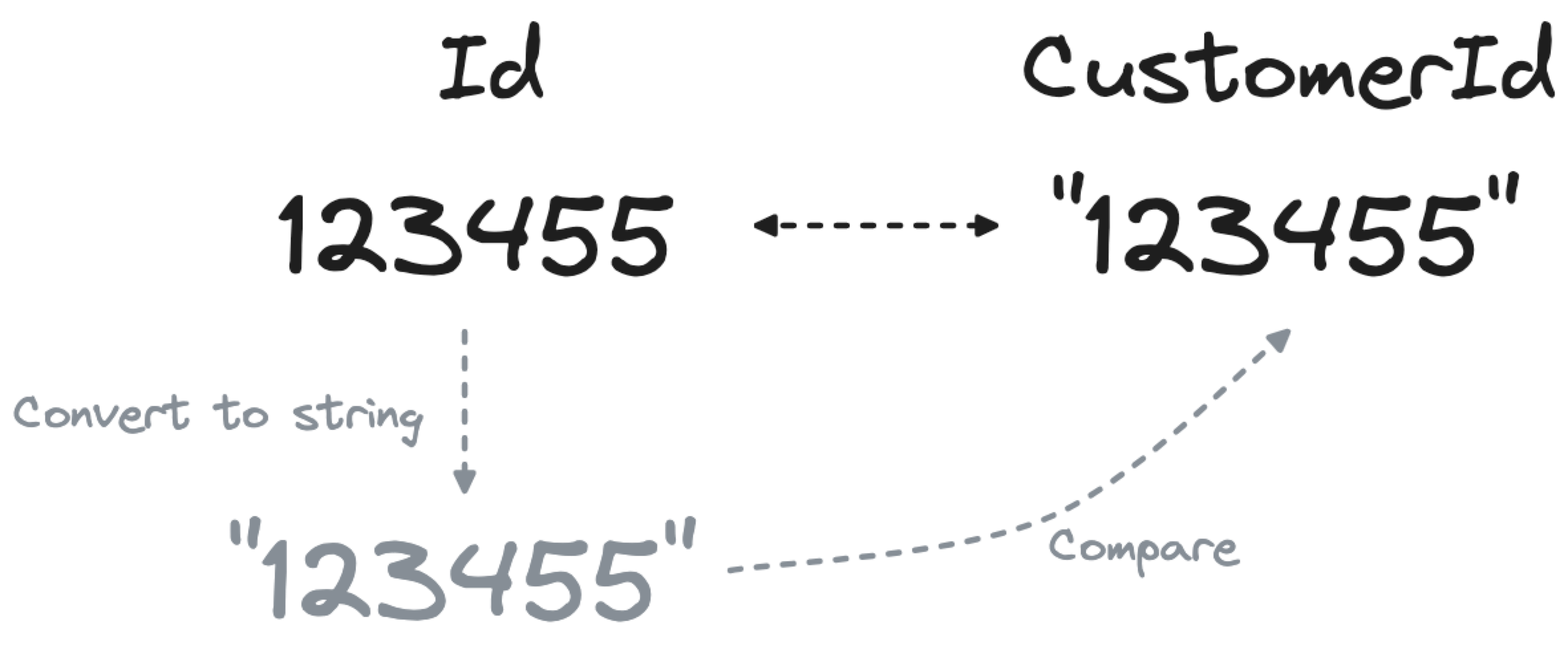
When joining two tables, ensure that the columns in the join condition are of the same type. Joining an integer Id column in one table with another customerId column defined as VARCHAR in another table will force the database to convert each Id to a string before comparing the results, slowing down the performance.
Warning
You can’t change the source field type at query time, but you can expose the data type inconsistency problem and fix it in the database table. When analyzing if the CustomerId field can be migrated from VARCHAR to INT, check that all the values in the column are integers indeed. If some of the values are not integers, you have a potential data quality problem.
Pro Tip
When in doubt, prefer more compact representations for your joining keys. If what you’re storing can be unambiguously defined as a number (e.g. a product code like 1234-678-234) prefer the number representation since it will:
- Use less disk
- Be faster to retrieve
- Be faster to join since integer comparison is quicker than the string version
However, beware of things that look like numbers but don't quite behave like them - for instance, telephone numbers like 015555555 where the leading zero is significant.
Optimize SELECT SQL queries by avoiding functions in joins
How
Similarly to the previous section, avoid unnecessary function usage in joins. Functions can prevent the database from using performance optimizations like leveraging indexes. Just think about the following query:
SELECT * FROM users JOIN orders ON UPPER(users.user_name) = orders.user_name
The above uses a function to transform the user_name field to upper case. However this could be a signal of poor data quality (and a missing foreign key) in the orders table that should be solved.
Warning
Queries like the one above can showcase a data quality problem solved at query time which is only a short term solution. Proper handling of data types and quality constraints should be a priority when designing data backend systems.
Golden rule
In a relational database, the joins between tables should be doable using the keys and foreign keys without any additional functions. If you find yourself needing to use a function, fix the data quality problem in the tables. In some edge cases using a function in conjunction with an index could help to speed up the comparison between complex or lengthy data types. For example, checking the equality between two long strings could potentially be accelerated by comparing initially only the first 50 characters, using the joining function UPPER(SUBSTR(users.user_name, 1, 50)) and an index on the same function.
Optimize SELECT SQL queries by avoiding joins
How
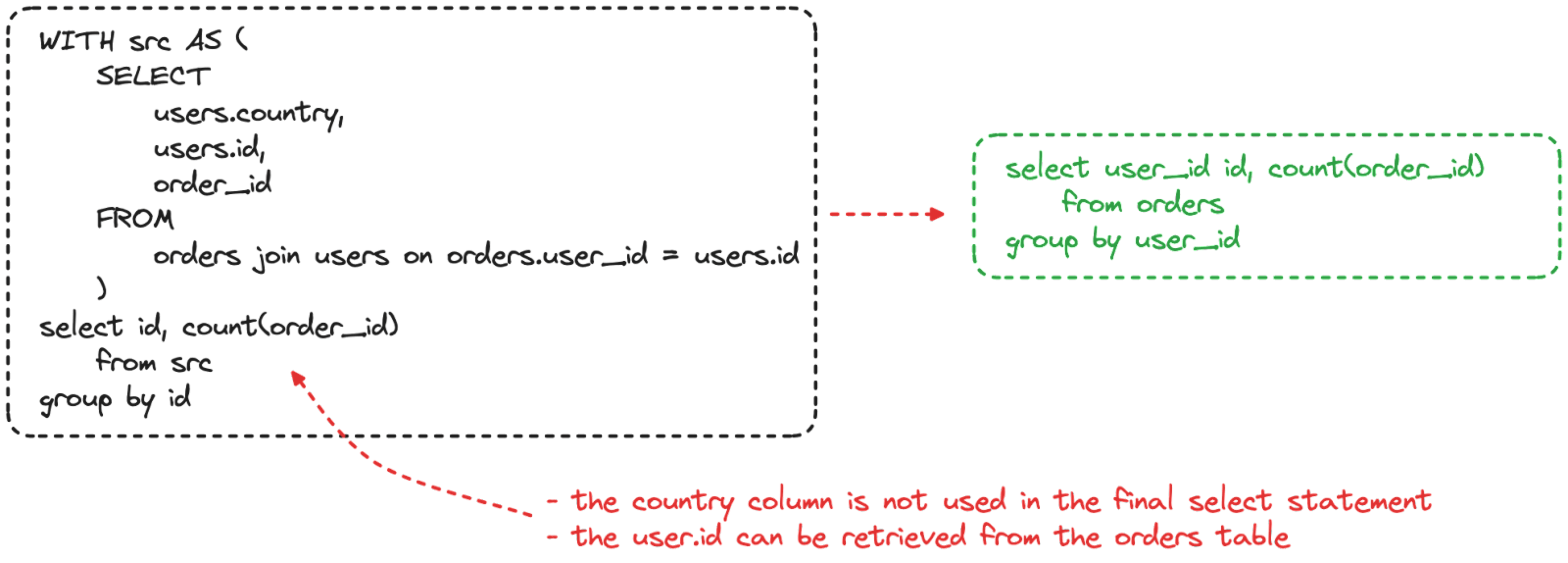
Queries can be built over time by different people and have a lot of sequential steps in the shape of CTE (common table expression). Therefore it might be difficult to understand the actual needs in terms of data inputs and outputs. Most of the time, when writing a query, you can add an extra field “just in case it is necessary” at a later stage. However this could have tremendous effects on performance if the field is coming from a new table requiring a join.
Always evaluate the strict data needs of the query and include only the columns and the tables which contain this information.
Warning
Double check if the join is needed to filter rows existing in both tables. In the example above, we could end up with incorrect results if there are user_id present in the orders table that are not stored in the id column of the users table.
Golden rule
Remove unnecessary joins. It is far more performant to generate a slimmer query to retrieve the overall dataset and then perform a lookup for more information only when necessary.
Pro Tip
The example explained above is just one case of JOIN overuse. Another example is when we are joining the data only to verify the presence of a row in another table. In such cases a subquery using EXISTS might be way faster than a join. Check a detailed example in the How to speed up COUNT(DISTINCT) blog.
Optimize SELECT SQL queries by improving filtering
After analyzing the JOIN condition it is now time to evaluate and improve the WHERE part of the query. Like the section above, subtle changes to the filtering statement can have a massive impact on query performance.
Optimize SELECT SQL queries by avoiding functions in filtering
How
Applying a function to a column in the filtering phase slows down the performance. The database needs to apply the function to the dataset before filtering. Let’s take a simple example of filtering on a timestamp field:
SELECT count(*) FROM orders WHERE CAST(order_timestamp AS DATE) > '2024-02-01';
The above query on a 100.000.000 row dataset runs in 01 min 53 sec because it needs to change the data type of the order_timestamp column from timestamp to date before applying the filter. But, that’s not necessary! As EverSQL by Aiven suggests, if you give it the above query and table metadata, it can be rewritten to:
SELECT count(*) FROM orders WHERE order_timestamp > '2024-02-01 00:00:00';
The rewritten query uses the native timestamp field without casting. The result of such small change is that the query now runs in 20 sec, nearly 6 times faster than the original.

Warning
Not all functions can be avoided, since some might be needed to retrieve parts of the column value (think about substring examples) or to reshape it. Nevertheless, every time you are about to add a function in a filter, think about alternative ways to use the native data type operators.
Golden rule
When applying a filter to a column, try to reshape the filter format rather than the column format.
The above is a perfect example: moving the filter format from the date 2024-02-01 to the timestamp 2024-02-01 00:00:00 allowed us to use the native timestamp data format and operators.
Pro Tip
If applying the function is a must, you can try the following two options:
- Create an index on the expression, available in PostgreSQL and MySQL
- Use database triggers to populate an additional column with the transformation already in place
Optimize SELECT SQL queries by improving subqueries
How
Subqueries are commonly used in filters to retrieve the set of values to be applied as filters. A common example is when needing to retrieve the list of users having recent activity.
SELECT * FROM users WHERE id IN ( SELECT DISTINCT user_id FROM sessions WHERE session_date = '2024-02-01');
The above query retrieves the distinct list of users from the SESSIONS table and then applies the filter on the USERS table. However, there are several, more performant, ways of achieving the same results. An example is using EXISTS:
SELECT * FROM users WHERE EXISTS ( SELECT user_id FROM sessions WHERE user_id = id and session_date = '2024-02-01' );
EXISTS is faster since it doesn’t need to retrieve the list of distinct users from the SESSION table, but it just verifies the presence of at least one row in the table for a specific user. The use case above went from a performance of 02 min 08 sec to 18 sec by just changing the subquery section.
Warning
Subtle changes in the subquery could provide different results in corner cases. For an example of subtle differences in execution and result set check out 5 Ways to implement NOT EXISTS in PostgreSQL
Golden rule
When needing to use subqueries, take time to learn and understand what are the options and what they allow you to achieve. Several times there’s more than one option and some functionalities will provide better response times.
Optimize SELECT SQL queries by paginating results
How
When needing to display a long list of rows, it’s useful to paginate the results retrieved from the database. Both PostgreSQL and MySQL offer the functionality to LIMIT the output to retrieve only a certain amount of rows and to OFFSET the result set by retrieving only rows in a specific range based on ordering. Using LIMIT and OFFSET is a good way to minimize the data sent to clients to only the one needed to be displayed.
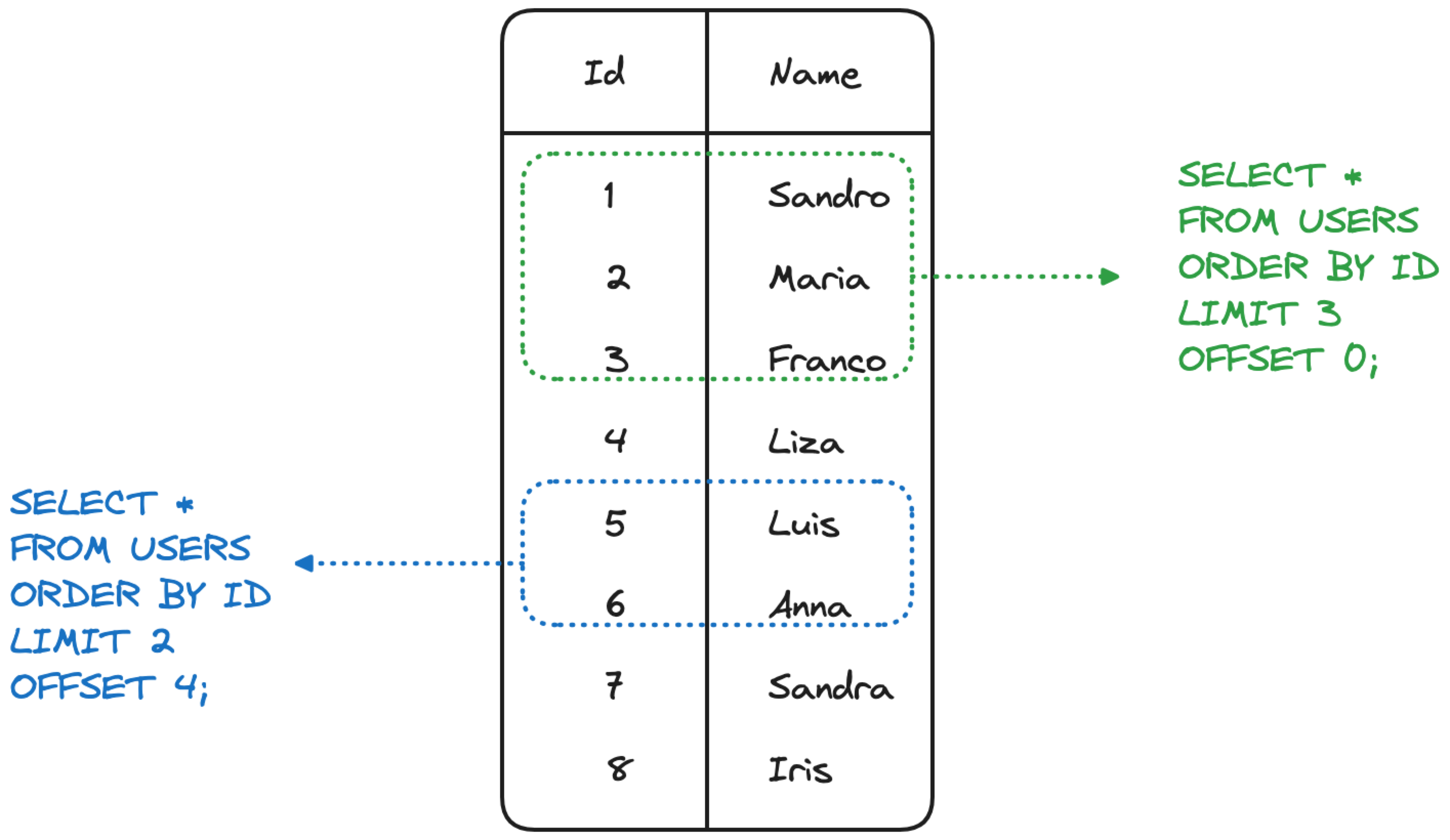
Warning
The drawback of using LIMIT and OFFSET is that you’ll need a query for each “page” to be sent and executed to the database. This could be inconvenient if the overall number of rows is not far from the page size. As example, if you’re showing results in pages of 10 rows, but there are on average 15 rows to display, it might be better to retrieve the entire dataset at once.
Golden rule
If the size of the resultset is an order of magnitude larger than the page size, using paging can be an effective way to ensure better performance, since only the visible dataset will be retrieved from the database.
Pro tip
The LIMIT and OFFSET clauses are the default pagination method in most databases. However, more efficient paging implementations can be achieved by storing the starting and ending offsets of the current page on the client side and pushing the filtering for the following page in the WHERE clause of the SQL statement. A couple of examples of this implementation are available in the Pagination done the PostgreSQL Way presentation by Markus Winand and in the faster pagination in MySQL blog.
Optimize SELECT SQL queries by moving filters from HAVING to WHERE clause
How
When running a query the filters defined in the WHERE and HAVING clauses are applied at different times:
- The
WHEREfilters are applied on the raw dataset, before any data transformation defined in theSELECTstatement is applied - The
HAVINGfilters are applied post aggregation, therefore after all the rows have been retrieved, transformed and rolled up.
Therefore moving filters in the WHERE section should be a priority since it allows you to work on a smaller dataset. An example is if we try to get the list of dates for which we have a session with a tracked user_id (the user_id field is not null, to know more about the difference check the COUNT DISTINCT blog post)
SELECT session_date, count(user_id) nr_sessions FROM sessions GROUP BY session_date HAVING count(user_id) > 0;
We can rewrite the above query by pushing the filter into the WHERE clause with:
SELECT session_date, count(user_id) nr_sessions FROM sessions WHERE user_id is not null GROUP BY session_date
The query performance, on a 100.000.000 rows dataset went from 21 sec to 18 sec with just a change in the filters statement.
Warning
Moving filters from the HAVING to the WHERE clause is possible only if we can determine a similar condition that applies at row level instead of the one applying at aggregate level.
Golden rule
Always try to filter in the WHERE clause since the filtering applies before the data is transformed/aggregated by the SELECT statement.
Optimize SELECT SQL queries by defining the columns to be retrieved
How
When querying a table, it’s key to identify which columns need to be retrieved. The SELECT * FROM TBL is often used as a shortcut to retrieve all columns and then define which need to be shown at a later stage, however when doing so, more data needs to be retrieved from the database and transmitted, impacting the performance.

Warning
It's not only that using SELECT * FROM TBL often retrieves more data than necessary, it is also prone to errors. Just think about a new column being added, that is instantly shown in an application or a removed column in the database now breaking the front-end parsing. By cautiously defining the list of columns to be retrieved you precisely state the data needs of your query.
Golden rule
Every SELECT statement should only define the list of columns needed to accomplish the job.
Optimize SELECT SQL queries by using aggregate functions
How
Sometimes the objective is to query a table to get the overall count of rows, or the aggregate value for a certain set of columns. In such cases extracting all the data from the database and performing the computation elsewhere is a bad idea. We can make use of the native database aggregation functionality to make the computation where the data resides, move less data around and achieve better overall performance.

If you’re trying to count the distinct values within columns, we have an article dedicated to how to enhance the COUNT DISTINCT query speed.
Warning
While database aggregate functions cover a wide range of needs (see PostgreSQL and MySQL), they might not contain the exact calculation you need to perform. In such cases, understand what is the minimal granularity you need to extract and aggregate at that level.
Golden rule
When needing to perform aggregation, check the database functions available. Despite the fact that one of the database scaling rules is to be biased towards client side, pushing the aggregation there, it is often worth using the aggregations server side to diminish the amount of data transmitted to the client. Moreover, databases can implement advanced techniques to optimize the aggregation calculation.
Optimize SELECT SQL queries by using window functions
How
Window functions, available in PostgreSQL and MySQL, provide a way to calculate aggregated values and compare them with the current row value. They can be really useful when needing, for example, to calculate the overall contribution of a certain sale to the overall country total. Using window functions allows you to simplify the query SQL and take advantage of the database optimizer to decide the best set of actions needed to retrieve the data.
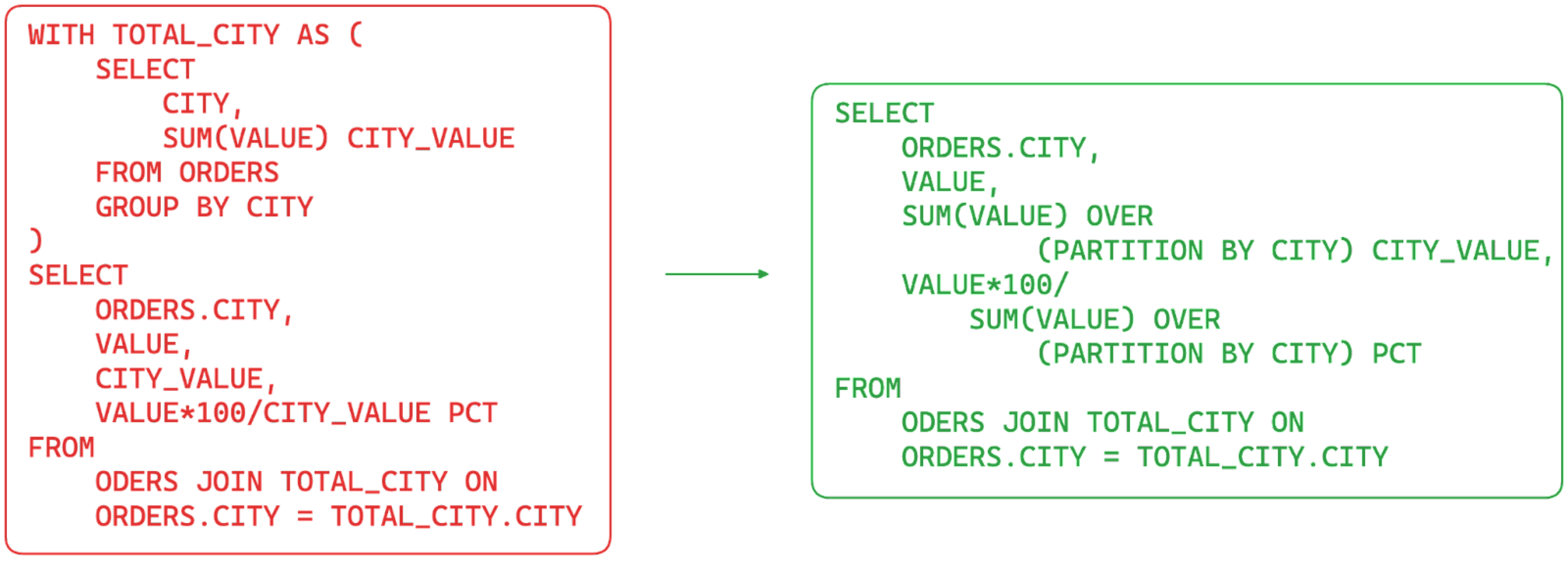
Warning
Window functions don’t change the cardinality of the dataset. For example, if you’re retrieving data at ORDER level, the window function will still emit one line per order. Evaluate the cardinality of data you need in the output and then decide whether to use window or aggregate functions.
Golden rule
Similarly to above, adopting window functions can be a powerful method to pre-compute calculations before sending data to clients. Yet the code to generate them is quite verbose. Define your priority between full query SQL optimization and code readability and maintainability.
Pro tip
The windows functions are not only useful for aggregating content at a certain level, but they also expose an ORDER BY statement allowing you to perform running calculations.
Optimize SELECT SQL queries by using partitions
How
Another technique to speed up SELECT performance, is to segment the data into multiple sub-tables called partitions. Partitioning is available in PostgreSQL and MySQL to split the data across a number of tables depending on a predicate. If you frequently need to retrieve the data with a specific filter, for example a date, you might want to organize it in different partitions, one per day, so the majority of queries will only scan a partition instead of the whole data set.

Warning
Despite partitioning being “invisible” from the user (a certain user can query the original table and select data from all partitions), you need to take into account its management. Specifically for LIST partitioning, when a new key is inserted, a proper partition needs to be created upfront otherwise the insert will fail.
Golden rule
Partitioning can be very useful in contexts where there are consistent query patterns filtering the dataset using the same key. Partitioning tables without clear filtering criteria only adds workload to the database, making every query slower.
Optimize SELECT SQL queries by using materialized views
How
Materialized views, available in PostgreSQL, are a great way to speed up SELECT statements by pre-calculating the results. Materialized views differ from standard views since:
- They store the result of the query in a table
- They need to be refreshed to provide up-to-date results
Still, if you have read intense environments with rare writes, paying the price for a materialized view refresh that can be used by several reads might be an optimal method to increase your query performance.

Warning
As mentioned above, materialized views are static objects, they are not automatically updated on every insert/update/deletion of the underlying set of tables. Therefore it is crucial to keep in mind that querying a materialized view could provide different results from querying the original tables.
Golden rule
If your primary goal is to have better performance at the cost of not retrieving up-to-date results, then materialized views are a perfect solution. Keep in mind that materialized views occupy space on disk and their creation or refresh are time and performance consuming.
Pro tip
Materialized views are great in cases where complex queries are scanning data in the past that can’t be updated. In such cases creating a materialized view for old data and querying the source tables live for fresh data could be a good mix of providing optimal performance without reporting stale data.
How to optimize INSERT SQL queries
Optimize INSERT SQL queries by using dedicated functionality
How
The standard practice to load data in a database is to use the INSERT statement. However some databases have dedicated tooling to insert big chunks of data directly from source files in a variety of formats like binary or CSV.
Tools like PostgreSQL COPY or MySQL LOAD DATA allow you to directly point to a CSV or binary file and are optimized for loading huge amounts of data, usually resulting in faster ingestion times compared to a series of INSERT statements.
Warning
While both PostgreSQL COPY or MySQL LOAD DATA will be faster than loading each row in a separate INSERT statement, they will both load the data in one big transaction putting the database under stress. Moreover, the long transaction will also be a bottleneck in the replication process, increasing the lag while the replicas are replaying it. Moreover, if a backup is taken while the big transaction is happening, a restore will be forced to rollback all the changes already stored in the backup, making the restore process slower.
Golden rule
Try to find the optimal spot between ingestion throughput and transaction size. Splitting a massive data file in smaller chunks and loading it using PostgreSQL COPY or MySQL LOAD DATA could be the perfect middleground giving you the required speed but not adding too much stress to the database.
Pro tip
If the data in the source file doesn’t match the format of the target table(s), reshaping the source data properly by using an external script might be faster than loading the data in a temporary table and then reshaping it in the database.
Optimize INSERT SQL queries by removing unnecessary indexes
How
Indexes are widely adopted to speed up database read patterns, however they create a penalty for every write operation (INSERT/UPDATE/DELETE) since the database needs to update both the source table and the index.
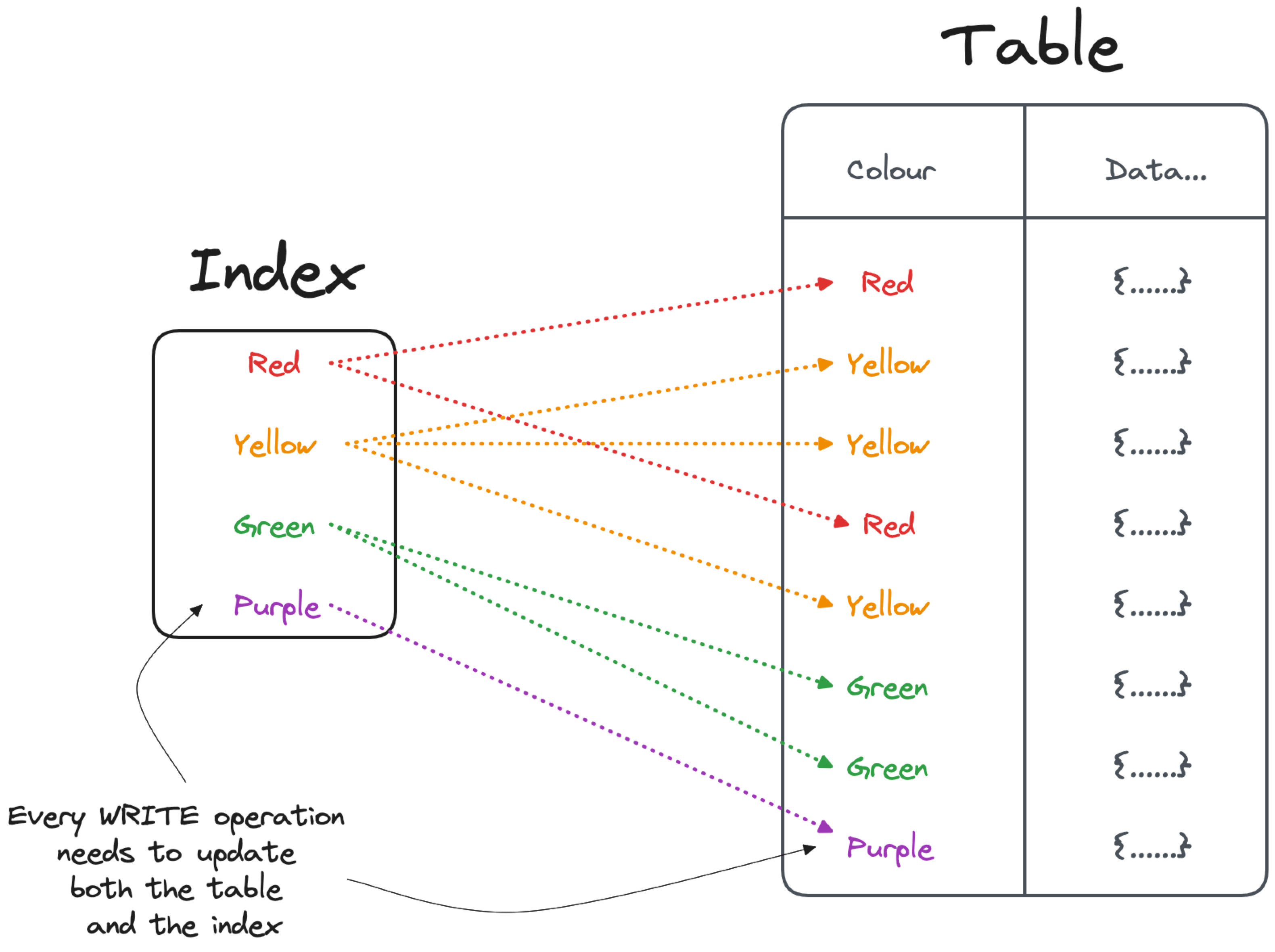
Therefore, to optimize write workloads, you might want to check if all the indexes in your table(s) are necessary and actively used by your read patterns. To check indexes usage, you can rely on the database system tables, like PostgreSQL pg_stat_user_indexes or the MySQL table_io_waits_summary_by_index_usage, providing up-to-date statistics about queries impacting the indexes. An example of PostgreSQL 16 pg_stat_user_indexes output is the following:
relid | indexrelid | schemaname | relname | indexrelname | idx_scan | last_idx_scan | idx_tup_read | idx_tup_fetch -------+------------+------------+---------+------------------+----------+-------------------------------+--------------+--------------- 16460 | 16466 | public | orders | idx_order_date | 1 | 2024-01-01 11:15:10.410511+00 | 10 | 10 16460 | 16465 | public | orders | idx_order_status | 4 | 2024-02-08 11:16:00.471185+00 | 0 | 0 (2 rows)
Where we can see that both the idx_order_date and idx_order_status indexes have been scanned one and four times respectively, with idx_order_date being scanned the last time on 2024-01-01 11:15:10.410511+00. Since the index hasn’t been used since January, it could be a good candidate for deletion.
EverSQL by Aiven provides a redundant index detection capability that can automate the discovery of unused indexes.
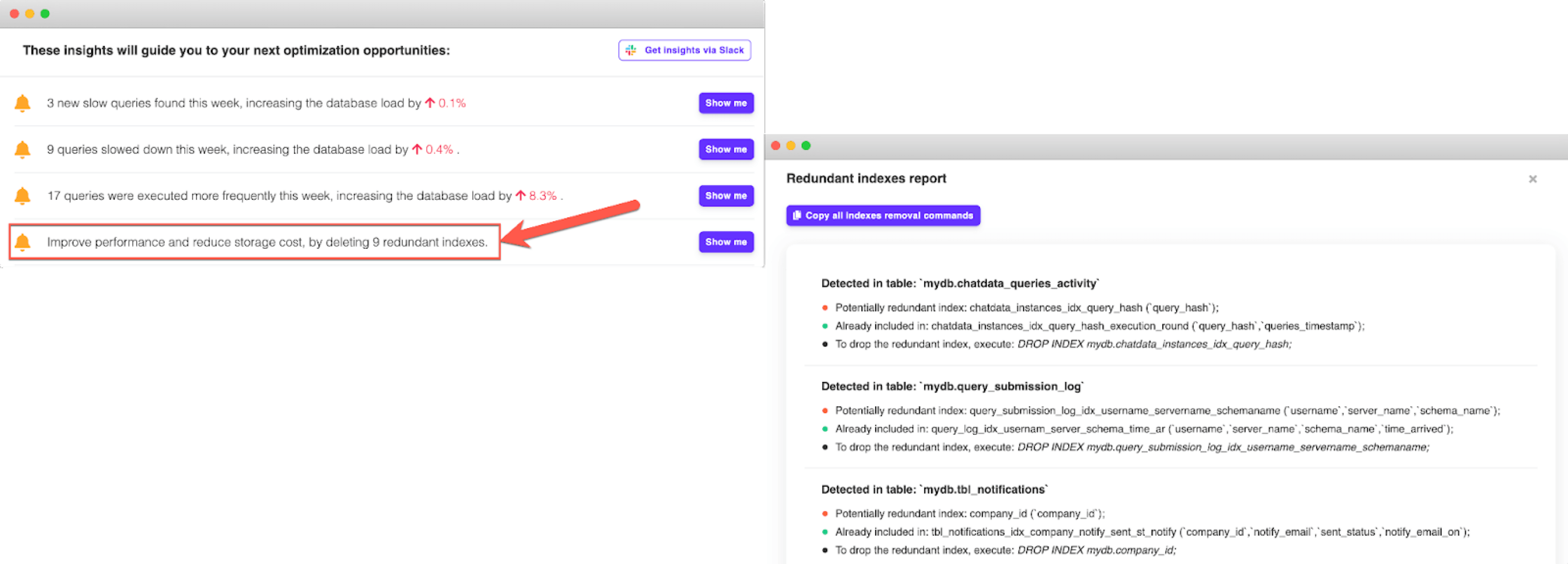
Once you identify unused indexes, dropping them will provide benefits in terms of write performance and less disk space usage.
Warning
Indexes are key to speed up read operations, and dropping them could have an impact on all SELECT queries. Understanding the read/write patterns in your database is crucial to optimize the whole experience rather than just one ingestion statement.
Golden rule
Analyze the overall database workload and define performance optimization priorities. Based on these, evaluate the overall set of indexes available and define which need to be kept or can be dropped.
Pro tip
If your data load statements happen during quiet read timings, like when loading a data warehouse overnight, you might obtain better ingestion performances by:
- Disabling indexes
- Loading the data
- Re-enabling indexes
Optimize INSERT SQL queries as if it was a SELECT statement
How
In many cases INSERT statements contain business logic parts, exactly as SELECT queries, meaning they can contain WHERE clauses, subqueries, and more.
Extracting the internal part of the query and optimizing it (via indexing, partitioning, query rewriting, etc.) as if it was a SELECT query can result in performance improvements.
Warning
The INSERT is a write workload for the database, therefore you need to be cautious in finding the exact boundaries of where the business logic in the INSERT statement can be accelerated without compromising the read workload's performance.
Golden rule
If your INSERT statement is selecting data from another table(s) in the database you can follow the rules detailed in the SELECT section. If you have clear data boundaries used in both INSERT and SELECT statements (WHERE conditions), then partitioning the tables could speed up both processes.
How to optimize DELETE SQL queries
Optimize DELETE SQL queries by removing unnecessary indexes
How
Likewise insert also deletes (and updates) performance can benefit from removing unnecessary indexes.
Warning
Depending on the workload, deletes might not be as frequent as insert/updates. Over optimizing for deletes might have drawbacks in performance or complexity of more common read/write patterns.
Golden rule
Analyze the overall database workload and define performance optimization priorities. Based on these, evaluate the overall set of indexes available and define which need to be kept or can be dropped.
Optimize DELETE SQL queries by using TRUNCATE
How
If your aim is to delete all the rows from a table, TRUNCATE is your friend. Available in both PostgreSQL and MySQL (as well as other databases), the truncate doesn’t perform a tuple-by-tuple deletion but it just tells the database to store all the new table’s data in a new empty location. It’s therefore much faster compared to a DELETE FROM TABLE.
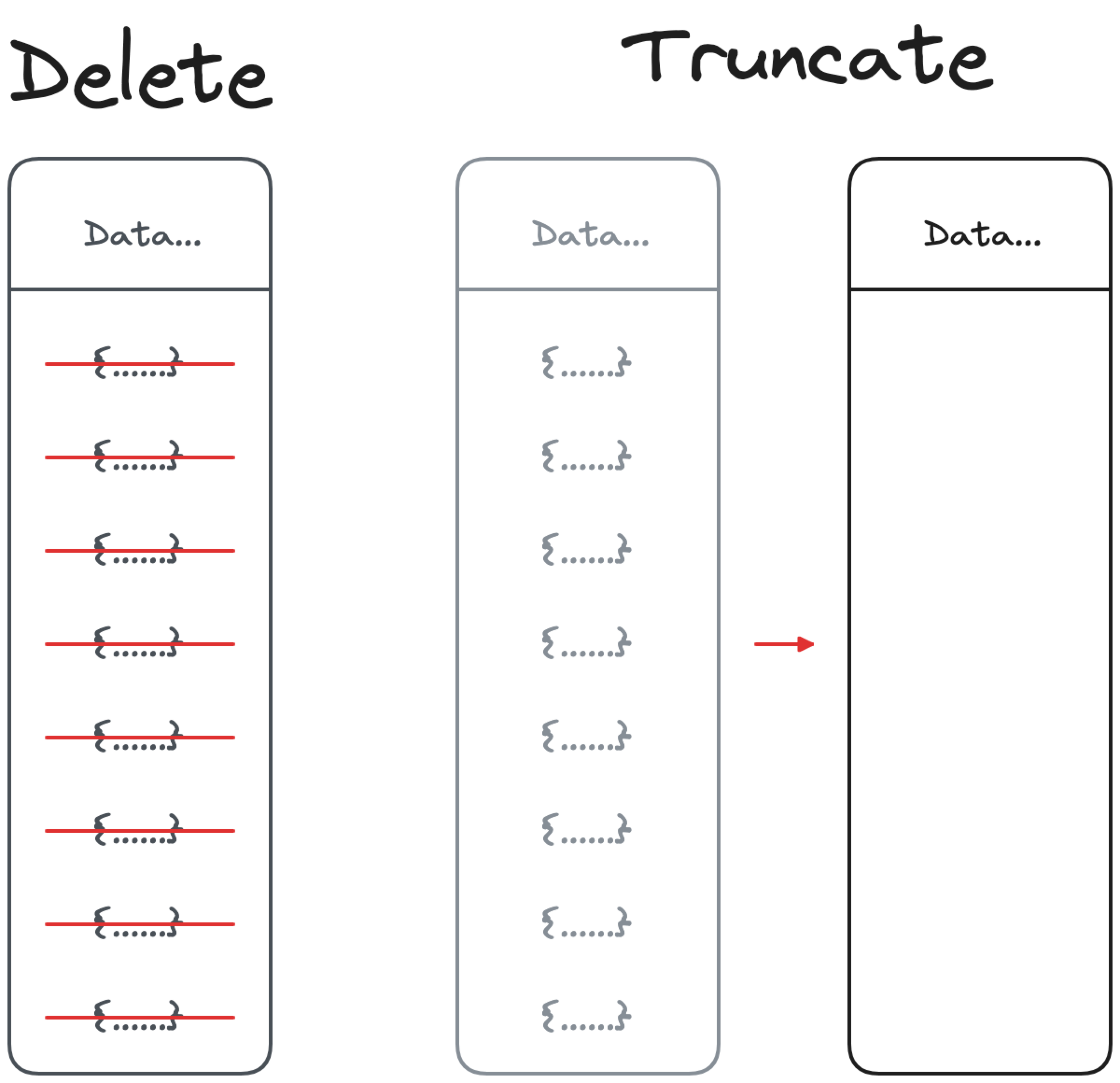
Warning
The truncate works only if you need to delete ALL the rows from a table. If you need only to delete a specific set of rows, this is not an option and possibly you should look at partitioning. TRUNCATE and DELETE have different privileges, needs and execution, understanding them (in MySQL and PostgreSQL) is key to ensure the correct operation is used.
Golden rule
When designing database tables, analyze your needs also in terms of data retention. If a table needs only to contain the “most recent” data, design it with both frequent inserts and deletes in mind.
Pro Tip
Using partitioning, or creating time bound tables (e.g. SALES_01_2024) can be a way to speed up deletions since an entire table can be truncated.
Optimize DELETE SQL queries by using table partitioning
How
Evolving the previous section, if your aim is to periodically delete data based on known rules, for example depending on a date field, you can use partitioning. Partitioning is available in PostgreSQL and MySQL to split the data across a number of tables depending on a predicate. If you need to delete the entire subset of the data included in a partition, you can simply truncate the partition itself.
The partitioning predicate could be either by:
- RANGE: defining a set of ranges associated with each partition in the table
- LIST: defining a fixed list of values associated with each partition in the table
- HASH: defining the partition based on a user-defined function
- KEY: available in MySQL, provides an HASH partitioning using MySQL hashing function
Warning
Despite partitioning being “invisible” from the user (a certain user can query the original table and select data from all partitions), the management of a partitioned table needs to be taken into account. Specifically for LIST partitioning, when a new key is inserted, a proper partition needs to be created upfront.
Golden rule
Partitioning can be very useful in contexts where there’s a clear boundary across the dataset in terms of time or other column (e.g. country). Partitioning tables without clear filtering criteria only adds workload to the database, making every query slower.
Optimize DELETE SQL queries by splitting the statements in chunks
How
When executing a massive DELETE operation, divide the amount of data to be removed in smaller chunks by applying additional WHERE conditions. With such technique you can obtain a process for easier to track, a faster rollback in case of failures and usually overall better performance.
Warning
Dividing a DELETE operation over multiple smaller statements exposes you to the risk of lacking consistency and missing some rows due to non-overlapping data subsets. Therefore you need to ensure to meet your consistency requirements, and that the set of statements generated contain the whole set of rows that the original query was addressing.
Golden rule
Splitting the DELETE operation in chunks can be a good method to speed up performance and generate less impact on the database at once. Apply this method if you have a specific set of data with clear boundaries for write and read operations (e.g. COUNTRY or DATE) that you can use as a splitting key.
Optimize DELETE SQL queries by executing DELETE less often
How
In some use-cases you might want to delete the data every day, for example when needing to delete old data older than 30 days. However, this operation will need to scan the whole table every day. For such use cases you can leverage a combined logic of:
- Not showing old results with smart
SELECTS(not retrieving data older than 30 days) - Deleting data only when space reclamation is useful (when running out of disk space)
Moreover, in PostgreSQL and MySQL, deleting a small portion of the dataset in a table is not going to lead to significant disk savings, since it will just generate free space in the pages hosting the table data.
Warning
You might be legally forced to delete old data on schedule. In this scenario evaluate your data retention needs wisely and plan data deletion accordingly. A smart partition design can help in providing fast deletion statements via truncate.
Golden rule
Design your data retention policies and related deletion statements wisely. Don’t plan for big space savings if you don’t plan to delete the majority of your dataset.
Optimize DELETE SQL queries by not executing the DELETE
How
If you’re deleting most of the data in a large table, it can be much faster to:
- Create a new table
- Copy the small portion that is still needed
- Drop the old table
- Rename the table
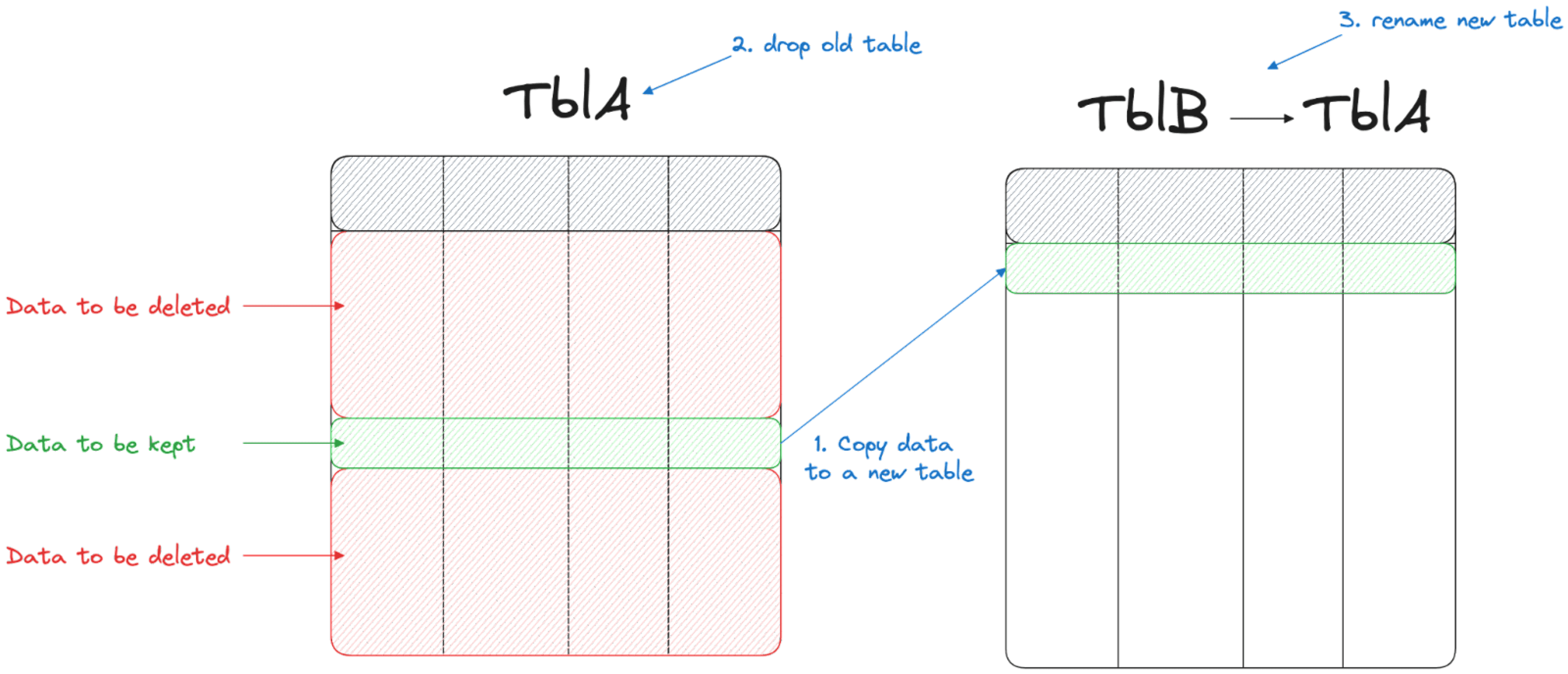
Warning
While this method might be quicker, it involves several operations in the database possibly preventing the normal functionality of the underlying tables. Be careful in understanding if you can perform the entire procedure while keeping the normal database functionality. Also, be mindful that this workaround will not work if you have referential constraints (like foreign keys pointing to some of the keys in the table).
Golden rule
Workarounds like the above are ideal in situations where the database load has easy to forecast usage patterns. Performing the process during a low peak of traffic (or when no traffic is there at all) will provide the best DELETE performance while minimizing the disruption for the entire database functionality.
Conclusion
Optimizing SQL statements can be a tedious task: you need to deeply understand both the database structures and the type of workload to optimize in order to achieve good results. Moreover, while optimizing a specific workload (for example an INSERT statement), you could impact the performance of other queries with different access patterns (like a SELECT or DELETE).
To have an holistic view of your data assets and supporting structures, understand performance variations and receive automatic, AI-assisted SQL optimization suggestions you can use EverSQL by Aiven. The EverSQL sensor, installed on any PostgreSQL and MySQL database, allows you to monitor slow queries and receive performance insights. The AI-driven engine analyzes your slow SQL statements, together with the existing supporting data structures, and provides both index recommendation and SQL rewrite suggestions to improve the performance.
Table of contents
- How to optimize SELECT SQL queries
- Optimize SELECT SQL queries by understanding the query execution plan
- Optimize SELECT SQL queries by using indexes
- Optimize SELECT SQL queries by improving joins
- Optimize SELECT SQL queries by improving filtering
- Optimize SELECT SQL queries by defining the columns to be retrieved
- Optimize SELECT SQL queries by using aggregate functions
- Optimize SELECT SQL queries by using window functions
- Optimize SELECT SQL queries by using partitions
- Optimize SELECT SQL queries by using materialized views
- How to optimize INSERT SQL queries
- Optimize INSERT SQL queries by using dedicated functionality
- Optimize INSERT SQL queries by removing unnecessary indexes
- Optimize INSERT SQL queries as if it was a SELECT statement
- How to optimize DELETE SQL queries
- Optimize DELETE SQL queries by removing unnecessary indexes
- Optimize DELETE SQL queries by using TRUNCATE
- Optimize DELETE SQL queries by using table partitioning
- Optimize DELETE SQL queries by splitting the statements in chunks
- Optimize DELETE SQL queries by executing DELETE less often
- Optimize DELETE SQL queries by not executing the DELETE
- Conclusion