Feb 8, 2023
Aiven for Apache Flink® is now generally available
With Aiven’s fully managed Apache Flink® service, you can leverage the power and flexibility of real time data processing.

Filip Yonov
|RSS FeedHead of Streaming Services
What is it worth to be first? First to identify a new trend, first to recognize an opportunity, first to recognize a risk or a threat, and to be the first to respond to it?
The answer is often ‘a lot’ – and sometimes that’s an understatement. According to recent research* over 80% of businesses say that transforming to a real time enterprise is critical to meeting customer expectations, yet only 12% have optimized their processes for real time customer experiences. One of the obvious reasons is that it's harder to remain responsive enough to stay in first place as you grow. This is true for both organizational scale and business complexity.
Utilizing technology is the key to success. Businesses are turning to real-time data from various sources such as connected devices, data-intensive applications and digital operations to drive their growth. Many organizations, including most of Aiven’s customers, have already adopted event streaming technologies like Apache Kafka® to help them detect and respond to changes in real time.
Apache Kafka is a proven, reliable way to make data available to the applications and services within any business in real time, but there is a growing need to process that data as it is being generated. And wouldn’t you want to do more than just respond to data or events - what about deriving value from it in real time?
This is where Apache Flink® comes in.
Apache Kafka and Apache Flink: the cornerstones of event streaming
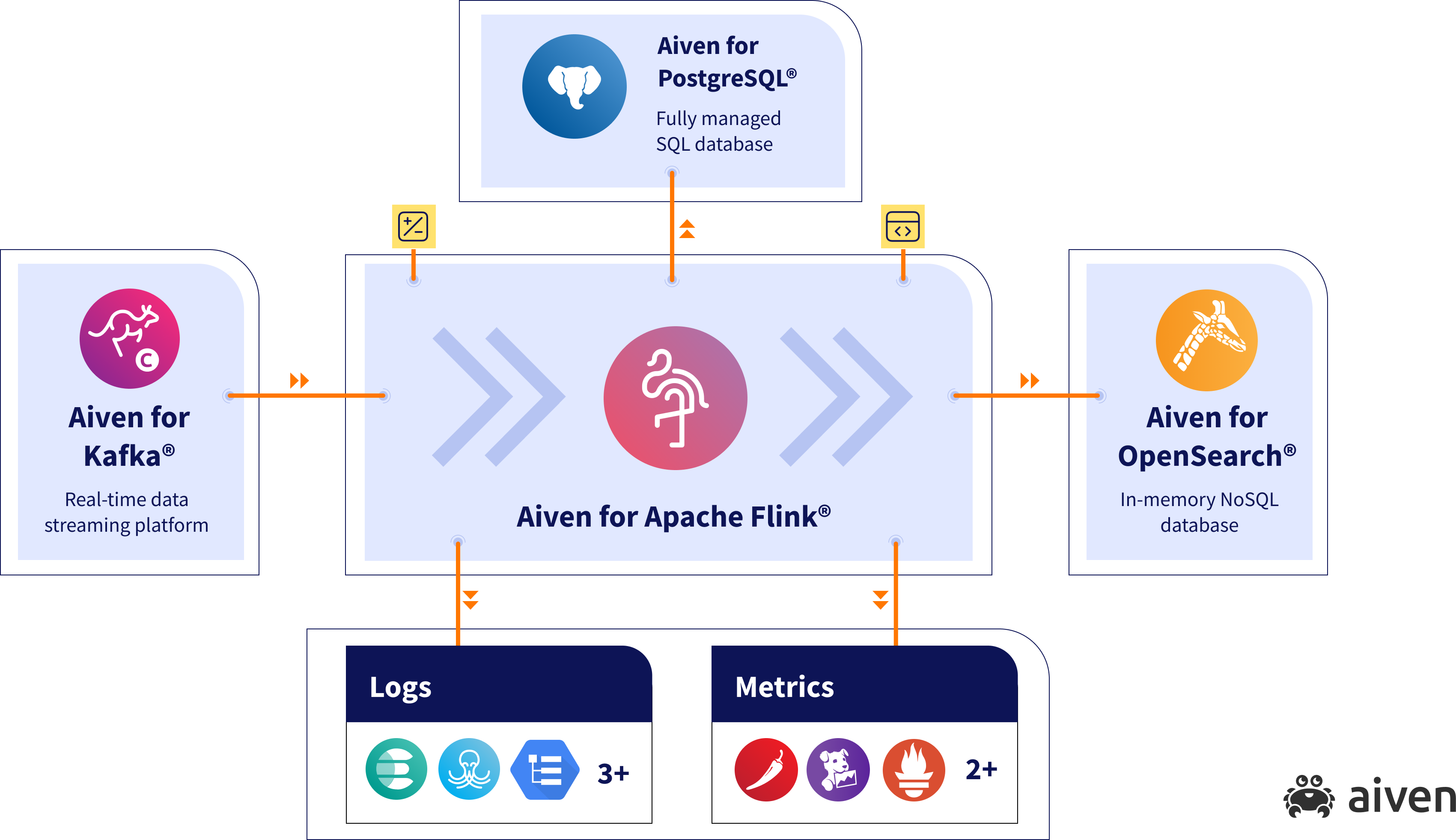
Together with Apache Kafka, Apache Flink enables you to create a robust event streaming infrastructure. Events can flow within the organization via Apache Kafka, while Apache Flink acts as the computational layer, and processes those events in real time. This combination is universally and widely applicable to a variety of industries and organizations of different sizes.
Apache Flink makes it easy to build, deploy and operate:
- Streaming analytics (analytics that are computed and updated in real time as new events are being produced and processed)
- Event-driven applications (these are applications that respond to such data in real time based on new events that are being processed)
Apache Flink® is an open source stream processing framework and distributed streaming runtime that originated as a research project from Technische Universität in Berlin, Germany (TU Berlin). In 2015, it became a top-level project under the Apache Software Foundation.
Apache Flink has been adopted and battle-tested by some of the largest and most technology-dependent organizations in the world, including Netflix, Pinterest and Uber. The framework can be used at varying levels of scale, and its ability to perform stateful computations over both streaming and batch data sets it apart. Apache Flink is a best-of-breed unified processing framework that can deliver significant value to organizations who are serious about utilizing their data in real time.
Aiven for Apache Flink now available
Today, we are excited to announce that the Aiven for Apache Flink® managed service is now generally available for all customers, and ready to use in production.
The Aiven team has worked with customers who experimented with the [Aiven for Apache Flink®] beta, taking on board their feedback and working on improvements. As a result, everyone can now take advantage of an easy-to-use stream processing service that is ready to support the real-time needs for organizations in all industries and sizes.
The Aiven for Apache Flink service stands on three key pillars:
- A fully managed Apache Flink service that can be deployed in the cloud of your choice
- A unique self-service Flink SQL suite, offering a first-class developer experience
- A Flink automation layer, Aiven's built-in management layer that eliminates the operational overhead of deploying, running, monitoring and managing open source Apache Flink. This provides instant maturity and production-ready data pipelines backed up by enterprise-grade availability SLA of 99.99%.
| Apache Flink deployed in the cloud of your choice | A self service Flink SQL developer experience | The utility of Flink without the operational overhead |
|---|---|---|
| Aiven’s managed service for Apache Flink allows you to distribute your cluster across multiple cloud providers including the three hyperscalers AWS, Google Cloud and Microsoft Azure. | Apache Flink SQL is at the core of Aiven for Apache Flink. A truly unified API for low latency stream processing; streaming SQL experience to democratize access to streaming data across teams; bringing coding best practices to building and maintaining streaming applications. | A fully managed service for Apache Flink with near-zero downtime for operational tasks, high availability and resilience from the get go, and a 99,99% SLA, backed by Aiven’s SRE team. |

Apache Flink deployed in the cloud of your choice
If you have a need to deploy applications & services across multiple cloud providers, but you want to reduce the complexity that comes with this requirement, Aiven can help. Our managed data infrastructure services can be deployed across multiple regions and cloud providers such as AWS, Google Cloud, and Microsoft Azure, giving your organization the flexibility to:
- Fulfill data residency requirements.
- Increase business resilience.
- Explore and exploit cost saving opportunities.
- Avoid potentially being locked into a single provider.
With data being replicated across multiple cloud providers, running parallel workloads on top of slightly different technologies represents an operational challenge and a considerable risk, especially for mission-critical and data-intensive workloads.
Aiven for Apache Flink solves this problem by providing a way to deploy and run your Apache Flink applications in different clouds. Without having to worry about the underlying infrastructure or puzzle over the specific requirements of each cloud vendor, you regain the flexibility to execute on your core business objectives. From today, you can quickly and easily spin up Aiven for Apache Flink clusters in more than 100 regions across AWS, Google Cloud and Microsoft Azure.
Additionally, with Aiven for Apache Flink, you’ll benefit from the same 99,99% availability SLA commitment across all clouds.
And on top of that, you get the same familiar and intuitive Aiven Console, CLI and API experience and the friendly Aiven support across all clouds, everywhere in the world.
A self-service Flink SQL developer experience
Aiven for Apache Flink brings Apache Flink SQL to center stage in enabling you to build unified, robust, and scalable event-driven applications and streaming analytics with your organization’s real time data.
SQL is the go-to language for data professionals, from data scientists and engineers to business analysts. With its widespread adoption, SQL allows for faster and more efficient data pipeline prototyping, validation, and deployment, which ultimately leads to faster time-to-market for a wide range of applications. Just imagine it: faster and more accurate decisions, just by having a common language for all your data teams across domains.
Flink SQL is the perfect framework for the job thanks to its wide set of SQL functions, and its extensive support and development by the Apache Flink community. Flink SQL offers a powerful, unified and declarative API built on top of Apache Flink. It enables performant computations on both bounded and unbounded data streams, making it suitable for a wide range of use cases, such as:
- Streaming analytics
- Data integration
- Pattern matching and anomaly detection
- AI and Machine Learning
It’s ANSI SQL compliant, integrated with Apache Calcite’s query optimization, and SQL parsing capabilities.
All this makes Flink SQL a technology that established organizations are already exploiting to great benefit.
In Aiven for Apache Flink, we are taking Flink SQL to the next level by bringing coding best practices to the construction of real time Apache Flink applications.
A redesigned interface with new capabilities.
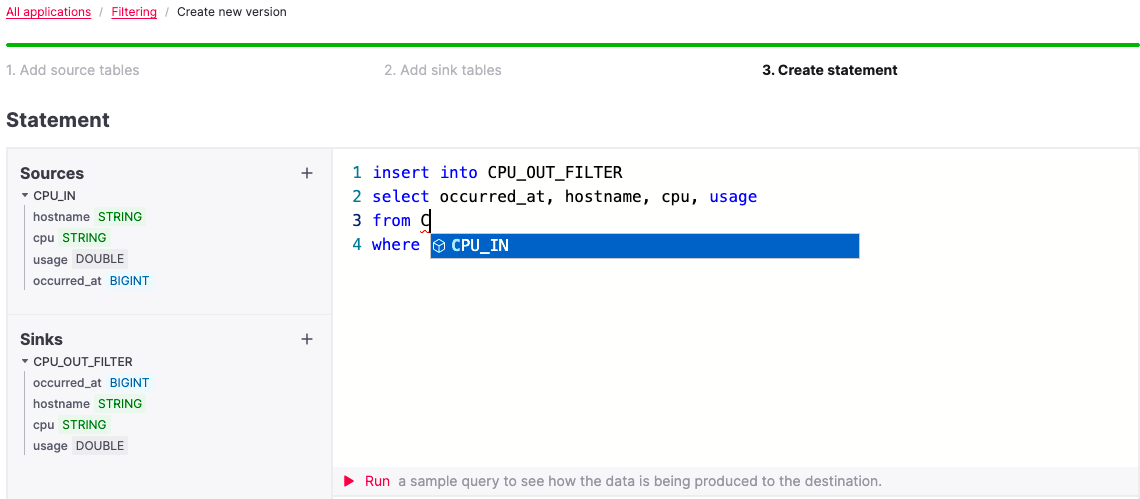
In Aiven for Apache Flink, we introduce the concept of ‘applications’ at the core of the development environment. An Application brings together all the elements of your Flink jobs (sink and source tables, transformation SQL, deployment parameters, checkpoints and more).
Application versioning
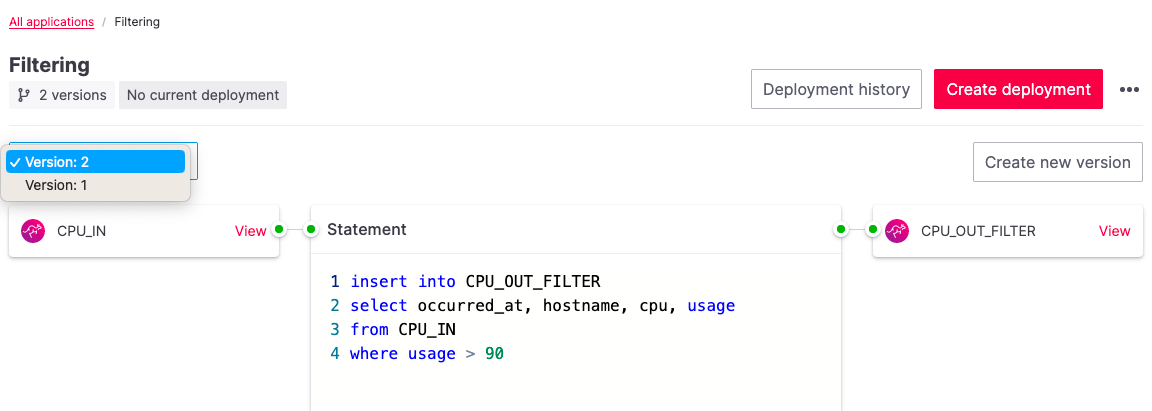
Define several versions of your Flink applications—you can easily ‘time travel’ in your development cycle with a click of a button and move between versions.
Pipeline output preview
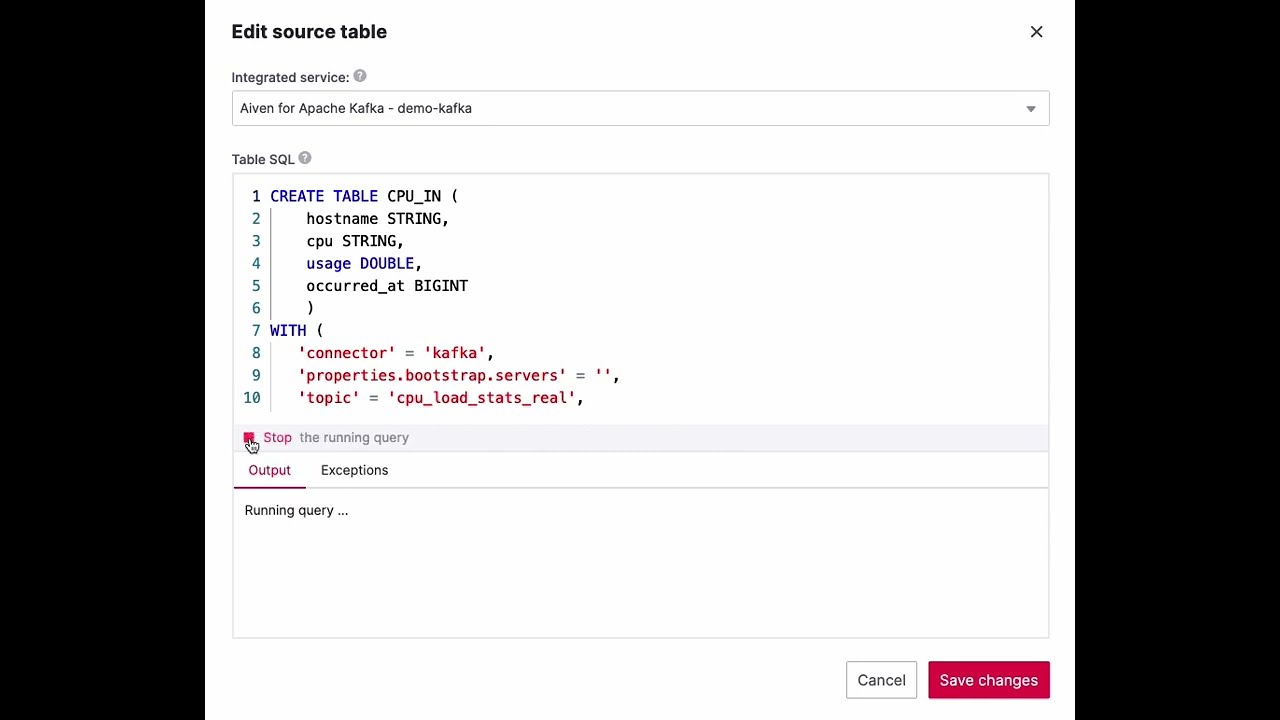
Aiven for Apache Flink enables the concept of previewing the output of your table definition and SQL transformation. This allows you to execute your Flink SQL query in your application and preview the first lines of the results to ensure that your code execution brings the expected outcome before moving ahead with your deployment.
All the utility of Apache Flink without the operational overhead
Managing your own Apache Flink jobs — be it on-premises or in a self-hosted or self-managed environment — can be difficult. This is especially the case when your jobs experience unpredictable and spiky data traffic fluctuations, which requires you to manually scale your infrastructure to ensure that high data loads are backed by all the necessary resources, whenever they occur.
Moving to a fully managed cloud service can be the solution. Using Aiven for Apache Flink automates most of the operational and maintenance activities around managing Flink in production:
- Easily scaling up (or down) your resources
Using the elasticity of the cloud, Aiven for Apache Flink allows you to easily scale up or down your resources with the click of a few buttons in the Aiven Console.
You can provision resources according to the data loads you expect Apache Flink to be processing on a daily/weekly/monthly basis. Another option is to set up an automated process that triggers service scale up or down based on the service workload. - Graceful shutdown with persisted savepoints
With Aiven for Apache Flink you can now gracefully shut down your Flink jobs. This ensures that your savepoints are persisted if you need to restart them later.
To add to all of the above, Aiven’s service for Apache Flink is backed by Aiven’s 99.99% SLA just like all our services.
Aiven now brings a robust, production-grade, easily deployed Apache Flink service and a streaming SQL engine able to handle most streaming SQL applications scenarios for the modern enterprise. You can really start building streaming applications in minutes, without worrying about managing and maintaining this piece of infrastructure. And most importantly, without worrying about your team’s management and maintenance overhead.
Pricing & availability
Aiven for Apache Flink is immediately available on all major hyperscalers - AWS, Google Cloud and Microsoft Azure - in over 100 regions globally.
All Aiven for Apache Flink plans come with a minimum of 3-node setup, providing resilience and high availability while ensuring minimal downtime even in the case of a node failure.
Aiven for Apache Flink is priced per hour, with prices starting from $0.57/h ($400/month).
Getting started with Aiven for Apache Flink
The easiest way to get started right now with Aiven for Apache Flink is to take advantage of our free trial with $300 free credits for a month.
Also check out our Aiven for Apache Flink product page and our developer documentation for more information and tips to help you get up to speed quickly.
Happy flinking!
P.S. If you already have a service running Aiven for Apache Kafka, take a look at how to connect it with our Aiven for Apache Flink service to get you up and running in no time.
Aiven for Apache Flink®
A fully managed service for Apache Flink for all your real time ETL and streaming analytics use cases.
Start your free trial*https://partners.wsj.com/aerospike/the-power-of-now/the-future-of-business-starts-right-now/
To get the latest news about Aiven and our services, plus a bit of extra around all things open source, subscribe to our monthly newsletter! Daily news about Aiven is available on our LinkedIn and Twitter feeds.
If you just want to find out about our service updates, follow our changelog.
Table of contents
- Apache Kafka and Apache Flink: the cornerstones of event streaming
- Aiven for Apache Flink now available
- Apache Flink deployed in the cloud of your choice
- A self-service Flink SQL developer experience
- All the utility of Apache Flink without the operational overhead
- Pricing & availability
- Getting started with Aiven for Apache Flink
Stay updated with Aiven
Subscribe for the latest news and insights on open source, Aiven offerings, and more.


