Mar 2, 2022
Real-time stock data with Apache Flink® and Apache Kafka®
With Apache Kafka® and Apache Flink®, you can now have coding-free support for real-time data processing and streaming analytics!

Felix Wu
|RSS FeedSolutions Architect at Aiven
Update / February 2023: Aiven for Apache Flink is generally available! Read more in our blog.

Apache Kafka® and Apache Flink can now support real-time data processing and streaming analytics! No code to write, only simple SQL Statements in Flink. You can have multiple sources or sinks of incoming data or processed data that are integrated into one Flink service.
Why you should use Flink
Flink is an open source tool that an enterprise can use for collaboration while still maintaining rigorous data governance. With Flink, engineers don’t have to build pipelines for each type of data separately. Instead, the data can be made available for teams and applications across the organisation with Flink jobs.
Data made to measure
With Flink jobs, you can filter, window, or enrich data according to the needs of the organisation. This data can then be passed on to other systems for storage or processing.
Fail fast, succeed faster
Adding new jobs via Aiven Console is easy and quick, which gives you more options for data handling. This makes Flink an ideal platform to run data experiments on.
Resilient data pipelines with Apache Flink
Flink offers a Highly Available platform for deploying data pipelines. Flink is configured with cluster restart strategy on fault tolerance, all Aiven business plans come with multi-nodes clusters that are highly available with automatic failover. More details explained here.
Microservices aren’t everything
Were you thinking of meeting organisational data needs with microservices? While that’s not a bad idea, note that with Flink, there’s no code to maintain, deploy or execute. That means less complexity, lower cost, quicker time-to-market, and resource savings.
Simple with a complex twist
Flink makes complex SQL joins and data windowing easy with its windows and watermarks; state is maintained in the Flink job.
In the following example, we have a table requests that collects web request access timestamps, we are going to query the number of requests per hour using PostgresSQL vs. Flink.
In PostgreSQL, you have to
with hours as ( select generate_series( date_trunc('hour', now()) - '1 day'::interval, date_trunc('hour', now()), '1 hour'::interval ) as hour ) select hours.hour, count(requests.id) from hours left join requests on date_trunc('hour', requests.accesstime) = hours.hour group by 1
... whereas in Flink you can
SELECT hour, count(id) FROM requests GROUP BY symbol, TUMBLE(accesstime, INTERVAL '1' HOUR)
Putting Flink to the test
Let's take a look at a real use case to show an end-to-end solution. This one simulates the processing of stock exchange data with Flink and Apache Kafka.
In the example, Python code generates stock exchange data into a Kafka topic. Flink then picks it up, processes it, and places the processed data into another Kafka topic.
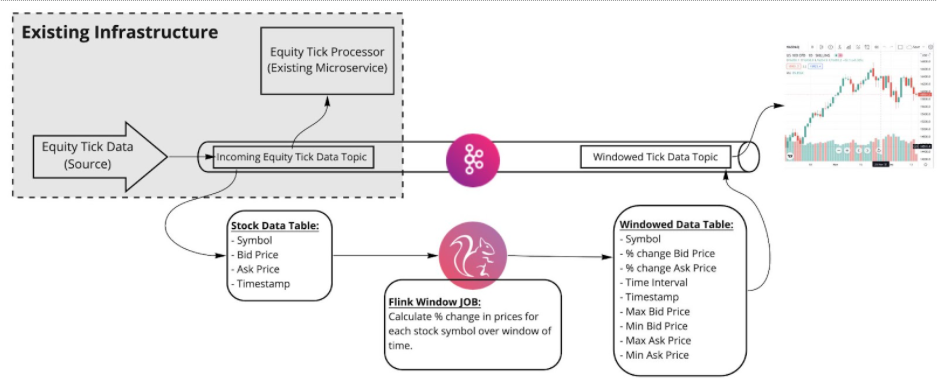
The following Flink query would do all this:
- calculate the difference between maximum and minimum bid price
- ask for the price of the equity tick data (stocks) over a time period
- track intervals of the stock during the specified time window (in this example, it is set to 9 seconds so the data flowing quicker within seconds for demonstration)
INSERT INTO ${aiven_flink_table.sink.table_name} SELECT symbol, max(bid_price)-min(bid_price), max(ask_price)-min(ask_price), min(bid_price), max(bid_price), min(ask_price), max(ask_price), TIMESTAMPDIFF(SECOND, min(ts_ltz),max(ts_ltz)), CURRENT_TIMESTAMP FROM ${aiven_flink_table.source.table_name} GROUP BY symbol, TUMBLE(ts_ltz, INTERVAL '9' SECOND)
But don’t take our word for it. To see this solution running live, take this code example. Set up Python 3 and Terraform, then follow the instructions. All it takes is a few commands for you to see the processed data.
Producer Example (generated stock data):
{"symbol": "M3", "bid_price": 16.89, "ask_price": 15.46, "time_stamp": 1637977977021} {"symbol": "KAFKA", "bid_price": 891.25, "ask_price": 891.75, "time_stamp": 1637977977046} {"symbol": "MYSQL", "bid_price": 667.94, "ask_price": 669.31, "time_stamp": 1637977977072} {"symbol": "PSQL", "bid_price": 792.25, "ask_price": 793.62, "time_stamp": 1637977977096} {"symbol": "INFLUX", "bid_price": 24.43, "ask_price": 24.79, "time_stamp": 1637977977124} {"symbol": "REDIS", "bid_price": 12.87, "ask_price": 12.57, "time_stamp": 1637977977150} {"symbol": "REDIS", "bid_price": 13.33, "ask_price": 12.26, "time_stamp": 1637977977178} {"symbol": "REDIS", "bid_price": 11.54, "ask_price": 11.29, "time_stamp": 1637977979703} {"symbol": "OS", "bid_price": 9.49, "ask_price": 10.3, "time_stamp": 1637977979731} {"symbol": "INFLUX", "bid_price": 24.44, "ask_price": 24.27, "time_stamp": 1637977979757} {"symbol": "CQL", "bid_price": 22.67, "ask_price": 21.61, "time_stamp": 1637977979788} {"symbol": "OS", "bid_price": 10.09, "ask_price": 10.49, "time_stamp": 1637977979813} {"symbol": "CQL", "bid_price": 22.06, "ask_price": 21.28, "time_stamp": 1637977979839} {"symbol": "MYSQL", "bid_price": 670.94, "ask_price": 669.85, "time_stamp": 1637977979864} {"symbol": "PSQL", "bid_price": 792.77, "ask_price": 792.24, "time_stamp": 1637977979889}
Consumer Example (processed stock data):
Received: b'{"symbol":"PSQL","change_bid_price":0,"change_ask_price":0,"min_bid_price":777.12,"max_bid_price":777.12,"min_ask_price":778.09,"max_ask_price":778.09,"time_interval":0,"time_stamp":"2021-11-27 01:52:33.744"}' Received: b'{"symbol":"INFLUX","change_bid_price":2.25,"change_ask_price":2.02,"min_bid_price":23.96,"max_bid_price":26.21,"min_ask_price":24.66,"max_ask_price":26.68,"time_interval":0,"time_stamp":"2021-11-27 01:52:33.744"}' Received: b'{"symbol":"M3","change_bid_price":0,"change_ask_price":0,"min_bid_price":26.57,"max_bid_price":26.57,"min_ask_price":25.9,"max_ask_price":25.9,"time_interval":0,"time_stamp":"2021-11-27 01:52:33.744"}' Received: b'{"symbol":"REDIS","change_bid_price":0,"change_ask_price":0,"min_bid_price":13.3,"max_bid_price":13.3,"min_ask_price":14.48,"max_ask_price":14.48,"time_interval":0,"time_stamp":"2021-11-27 01:52:33.745"}' Received: b'{"symbol":"OS","change_bid_price":1.52,"change_ask_price":1.92,"min_bid_price":19.04,"max_bid_price":20.56,"min_ask_price":18.61,"max_ask_price":20.53,"time_interval":0,"time_stamp":"2021-11-27 01:52:33.745"}' Received: b'{"symbol":"OS","change_bid_price":1.74,"change_ask_price":2.27,"min_bid_price":15.24,"max_bid_price":16.98,"min_ask_price":14.45,"max_ask_price":16.72,"time_interval":2,"time_stamp":"2021-11-27 01:52:42.358"}' Received: b'{"symbol":"MYSQL","change_bid_price":1.43,"change_ask_price":1.08,"min_bid_price":667.17,"max_bid_price":668.6,"min_ask_price":666.92,"max_ask_price":668,"time_interval":3,"time_stamp":"2021-11-27 01:52:42.358"}' Received: b'{"symbol":"REDIS","change_bid_price":2.7,"change_ask_price":4.31,"min_bid_price":12.98,"max_bid_price":15.68,"min_ask_price":11.55,"max_ask_price":15.86,"time_interval":3,"time_stamp":"2021-11-27 01:52:42.359"}'
Further reading
- An introduction to Apache Flink®
- Move from batch to streaming with Apache Kafka® and Apache Flink®
- Data and disaster recovery
- 5 benefits of an Apache Kafka centric microservice architecture
If you're not using Aiven for Apache Kafka® and our other services yet, go ahead and sign up now for your free trial at https://console.aiven.io/signup!
In the meantime, make sure you follow our changelog and blog RSS feeds or our LinkedIn and Twitter accounts to stay up-to-date with product and feature-related news.
Stay updated with Aiven
Subscribe for the latest news and insights on open source, Aiven offerings, and more.


