Consistent Change Data Capture across multiple tables with PostgreSQL® logical decoding, the outbox pattern and Debezium
Follow along to implement the outbox pattern in PostgreSQL® and create a change data capture workflow that doesn't create duplicate data!
Change data capture across multiple tables with PostgreSQL® logical decoding messages and Debezium
Change data capture (CDC) is a widely adopted pattern to move data across systems. While the basic principle works well on small single table use-cases, things get complicated when we need to take into account consistency when information spans multiple tables. In cases like this, creating multiple 1-1 CDC flows is not enough to guarantee a consistent view of the data in the database because each table is tracked separately. Aligning data with transaction boundaries becomes a hard and error prone problem to be solve once the data left the database.
This tutorial shows how to use PostgreSQL® logical decoding, the outbox pattern and Debezium to propagate a consistent view of a dataset spanning over multiple tables.
Debezium 2.5
This article describes the configuration for Debezium version 2.5 and later.Use case: A PostgreSQL based online shop
Relational databases are based on an entity-relationship model, where entities are stored in tables, with each table having a key for uniqueness. Relationships take the form of foreign keys, that allow information from various tables to be joined.
A practical example is the following with the three entities users, products, orders, and order lines and the relationships within them.
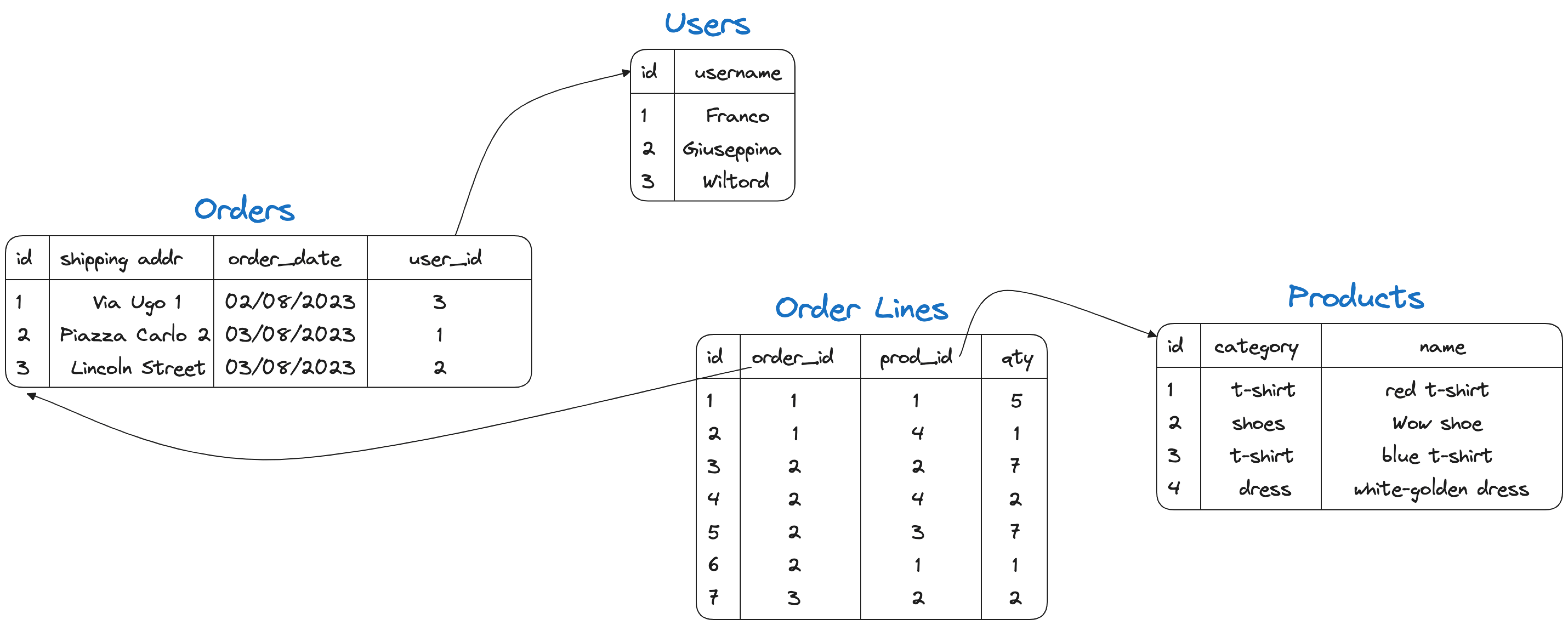
In the above picture, the orders table contains a foreign key to users (the user making the order), and the order lines table contains the foreign keys to orders and products allowing to understand to which order the line belongs and which products it includes.
We can recreate the above situation by signing up for an Aiven account and accessing the console, then creating a new Aiven for PostgreSQL® database. When the service is up and running, we can retrieve the connection URI from the service console page's Overview tab.
When you have the connection URI, connect with psql and run the following:
CREATE TABLE USERS (ID SERIAL PRIMARY KEY, USERNAME TEXT); INSERT INTO USERS (USERNAME) VALUES ('Franco'),('Giuseppina'),('Wiltord');
CREATE TABLE PRODUCTS ( ID SERIAL PRIMARY KEY, CATEGORY TEXT, NAME TEXT, PRICE INT ); INSERT INTO PRODUCTS (CATEGORY, NAME, PRICE) VALUES ('t-shirt', 'red t-shirt',5), ('shoes', 'Wow shoe',35), ('t-shirt', 'blue t-shirt',15), ('dress', 'white-golden dress',50);
CREATE TABLE ORDERS ( ID SERIAL PRIMARY KEY, SHIPPING_ADDR TEXT, ORDER_DATE DATE, USER_ID INT, CONSTRAINT FK_USER FOREIGN KEY(USER_ID) REFERENCES USERS(ID) ); INSERT INTO ORDERS (SHIPPING_ADDR, ORDER_DATE, USER_ID) VALUES ('Via Ugo 1', '02/08/2023',3), ('Piazza Carlo 2', '03/08/2023',1), ('Lincoln Street', '03/08/2023',2);
CREATE TABLE ORDER_LINES ( ID SERIAL PRIMARY KEY, ORDER_ID INT, PROD_ID INT, QTY INT, CONSTRAINT FK_ORDER FOREIGN KEY(ORDER_ID) REFERENCES ORDERS(ID), CONSTRAINT FK_PRODUCT FOREIGN KEY(PROD_ID) REFERENCES PRODUCTS(ID) ); INSERT INTO ORDER_LINES (ORDER_ID, PROD_ID, QTY) VALUES (1,1,5), (1,4,1), (2,2,7), (2,4,2), (2,3,7), (2,1,1), (3,2,2);
Start the Change Data Capture flow with the Debezium connector
Now, if we want to send an event to Apache Kafka® every time a new order happens we can define a Debezium CDC connector that includes all four tables defined above.
To do this, navigate to the Aiven Console and create a new Aiven for Apache Kafka® service (we need at least a Business plan for this example, so that we can run a Kafka Connector). Then
- Enable Kafka Connect from the Connectors tab of the service overview page.
- Navigate to the bottom of the Service Settings tab and enable the
kafka.auto_create_topics_enableconfiguration in the Advanced parameter section - this is not something we'd normally do in production, but it makes sense for our test purposes.
Finally, when the service is up and running create a Debezium CDC connector with the following JSON definition:
{ "name": "mysourcedebezium", "connector.class": "io.debezium.connector.postgresql.PostgresConnector", "database.hostname": "<HOSTNAME>", "database.port": "<PORT>", "database.user": "avnadmin", "database.password": "<PASSWORD>", "database.dbname": "defaultdb", "topic.prefix": "mydebprefix", "plugin.name": "pgoutput", "slot.name": "mydeb_slot", "publication.name": "mydeb_pub", "publication.autocreate.mode": "filtered", "table.include.list": "public.users,public.products,public.orders,public.order_lines" }
Where:
database.hostname,database.port,database.passwordspecify the Aiven for PostgreSQL connection parameters that can be found in the Aiven Console's service overview tabtopic.prefixis the prefix for the topic names in Aiven for Apache Kafkaplugin.nameis the PostgreSQL plugin to use,pgoutputslot.nameandpublication.nameare the name of the replication slot and publication in PostgreSQL"publication.autocreate.mode": "filtered"allows us to create a publication only for the tables in scopetable.include.listlists the tables for which we want to enable CDC
The connector will create four topics (one per table) and tracks the changes separately for each table.
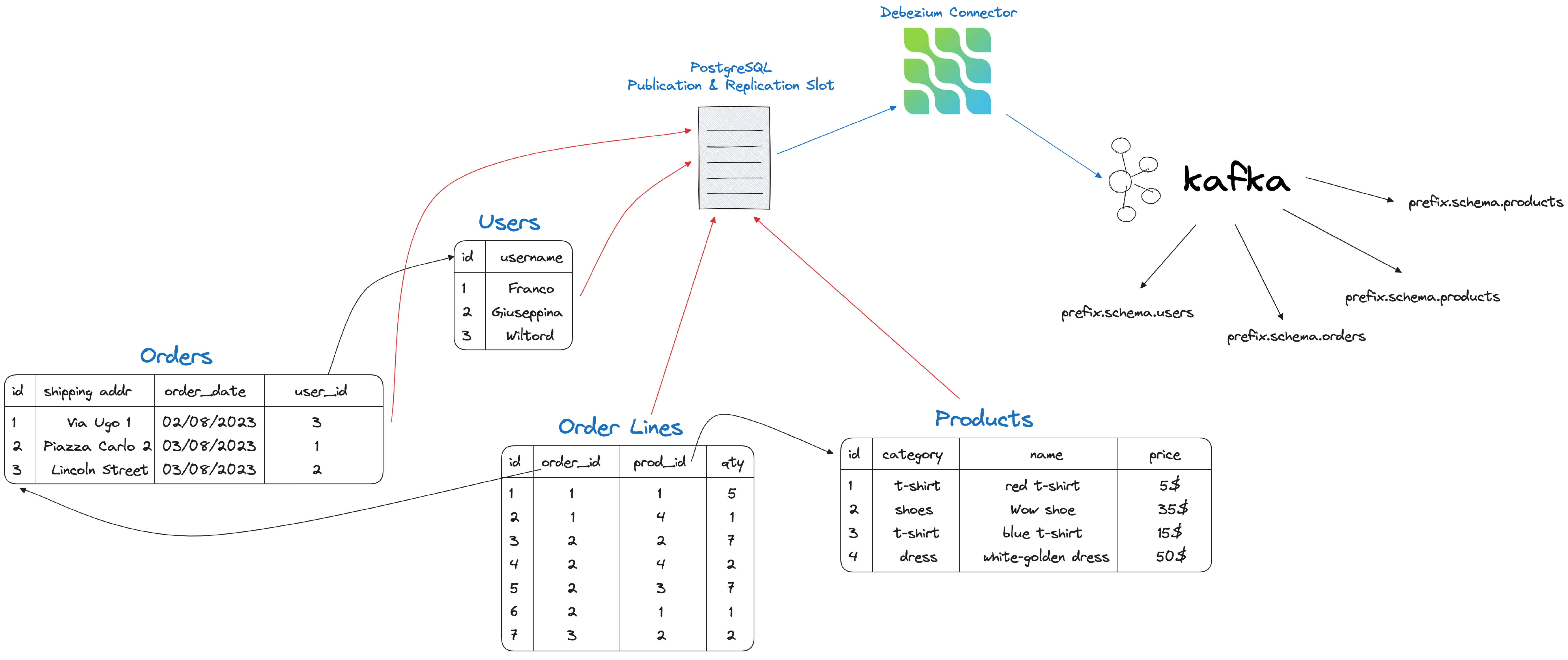
In Aiven for Apache Kafka we should see four different topics named <prefix>.<schema_name>.<table_name> where:
<prefix>matches thedatabase.server.nameparameter (mydebprefix)<schema_name>matches the name of the schema (publicin our scenario)<table_name>matches the name of the tables (users,products,orders, andorder_lines)
If we check with kcat, the mydebprefix.public.users log in Apache Kafka, we should see data similar to the below
{"before":null,"after":{"id":1,"username":"Franco"},"source":{"version":"2.5.0.Final.Aiven","connector":"postgresql","name":"mydebprefix","ts_ms":1733413858488,"snapshot":"first","db":"defaultdb","sequence":"[null,\"855639976\"]","schema":"public","table":"users","txId":2171,"lsn":855639976,"xmin":null},"op":"r","ts_ms":1733413858959,"transaction":null} {"before":null,"after":{"id":2,"username":"Giuseppina"},"source":{"version":"2.5.0.Final.Aiven","connector":"postgresql","name":"mydebprefix","ts_ms":1733413858488,"snapshot":"true","db":"defaultdb","sequence":"[null,\"855639976\"]","schema":"public","table":"users","txId":2171,"lsn":855639976,"xmin":null},"op":"r","ts_ms":1733413858959,"transaction":null} {"before":null,"after":{"id":3,"username":"Wiltord"},"source":{"version":"2.5.0.Final.Aiven","connector":"postgresql","name":"mydebprefix","ts_ms":1733413858488,"snapshot":"last_in_data_collection","db":"defaultdb","sequence":"[null,\"855639976\"]","schema":"public","table":"users","txId":2171,"lsn":855639976,"xmin":null},"op":"r","ts_ms":1733413858959,"transaction":null}
The above is the typical Debezium data representation with the before and after representations, as well as information about the transactions (ts_ms as example) and the data source (schema, table and others). This rich information will be useful later.
The consistency problem
Now let's say Franco, one of our users, decides to issue a new order for the white-golden dress. Just a few seconds later, our company, due to an online debate decides that the white-golden dress is now called blue-black dress and wants to charge 65$$ instead of the 50$$ original price.
.
 .
.The first action can be represented by the following transaction in PostgreSQL:
--- Franco purchasing the white-golden dress BEGIN; INSERT INTO ORDERS (SHIPPING_ADDR, ORDER_DATE, USER_ID) VALUES ('Piazza Carlo 2', '04/08/2023',1); INSERT INTO ORDER_LINES (ORDER_ID, PROD_ID, QTY) VALUES (4,4,1); END;
After which we can check the order details with the following query:
SELECT USERNAME, ORDERS.ID ORDER_ID, PRODUCTS.NAME PRODUCT_NAME, PRODUCTS.PRICE PRODUCT_PRICE, ORDER_LINES.QTY QUANTITY FROM USERS JOIN ORDERS ON USERS.ID = ORDERS.USER_ID JOIN ORDER_LINES ON ORDERS.ID = ORDER_LINES.ORDER_ID JOIN PRODUCTS ON ORDER_LINES.PROD_ID = PRODUCTS.ID WHERE ORDERS.ID = 4;
This should report the correct order details:
username | order_id | product_name | product_price | quantity ----------+----------+--------------------+---------------+---------- Franco | 4 | white-golden dress | 50 | 1 (1 row)
The second action can be represented by the following transaction:
--- Our company updating name and the price of the white-golden dress BEGIN; UPDATE PRODUCTS SET NAME = 'blue-black dress', PRICE = 65 WHERE ID = 4; END;
We can then repeat the query to find out the order details:
SELECT USERNAME, ORDERS.ID ORDER_ID, PRODUCTS.NAME PRODUCT_NAME, PRODUCTS.PRICE PRODUCT_PRICE, ORDER_LINES.QTY QUANTITY FROM USERS JOIN ORDERS ON USERS.ID = ORDERS.USER_ID JOIN ORDER_LINES ON ORDERS.ID = ORDER_LINES.ORDER_ID JOIN PRODUCTS ON ORDER_LINES.PROD_ID = PRODUCTS.ID WHERE ORDERS.ID = 4;
The result now shows the order as Franco ordering a blue-black dress with an extra $15 cost.
username | order_id | product_name | product_price | quantity ----------+----------+------------------+---------------+---------- Franco | 4 | blue-black dress | 65 | 1 (1 row)
Recreate consistency in Apache Kafka
When we look at the data in Apache Kafka, we can see all the changes in the topics. Browsing the mydebprefix.public.order_lines topic with kcat, we can check the new entry (the results in mydebprefix.public.orders would be similar):
{"before":null,"after":{"id":8,"order_id":4,"prod_id":4,"qty":1},"source":{"version":"2.5.0.Final.Aiven","connector":"postgresql","name":"mydebprefix","ts_ms":1733413959729,"snapshot":"false","db":"defaultdb","sequence":"[null,\"872415888\"]","schema":"public","table":"order_lines","txId":2182,"lsn":872415888,"xmin":null},"op":"c","ts_ms":1733413960339,"transaction":null}
And in mydebprefix.public.products, we can see entries like the following, showcasing the update from white-golden dress to blue-black dress and related price change:
{"before":null,"after":{"id":4,"category":"dress","name":"white-golden dress","price":50},"source":{"version":"2.5.0.Final.Aiven","connector":"postgresql","name":"mydebprefix","ts_ms":1733413858488,"snapshot":"last_in_data_collection","db":"defaultdb","sequence":"[null,\"855639976\"]","schema":"public","table":"products","txId":2171,"lsn":855639976,"xmin":null},"op":"r","ts_ms":1733413858972,"transaction":null} {"before":null,"after":{"id":4,"category":"dress","name":"blue-black dress","price":65},"source":{"version":"2.5.0.Final.Aiven","connector":"postgresql","name":"mydebprefix","ts_ms":1733413976945,"snapshot":"false","db":"defaultdb","sequence":"[\"872416184\",\"872416336\"]","schema":"public","table":"products","txId":2185,"lsn":872416336,"xmin":null},"op":"u","ts_ms":1733413977590,"transaction":null}
The question now is: How can we keep the order consistent with reality, where Franco purchased the white-golden dress for $50?
As mentioned before, the Debezium format stores lots of metadata in addition to the change data. We could make use of the transaction's metadata (txId, lsn and ts_ms for example) and additional tools like Aiven for Apache Flink® to recreate a consistent view of the transaction via stream processing. That solution requires additional tooling that might not be in scope for us, however.
Use the outbox pattern in PostgreSQL
An alternative solution that doesn't require additional tooling is to propagate a consistent view of the data using an outbox pattern built in PostgreSQL. With the outbox pattern we store, alongside the original set of tables, an additional table which consolidates the information. With this pattern we can update both the original table and the outbox one within a transaction.
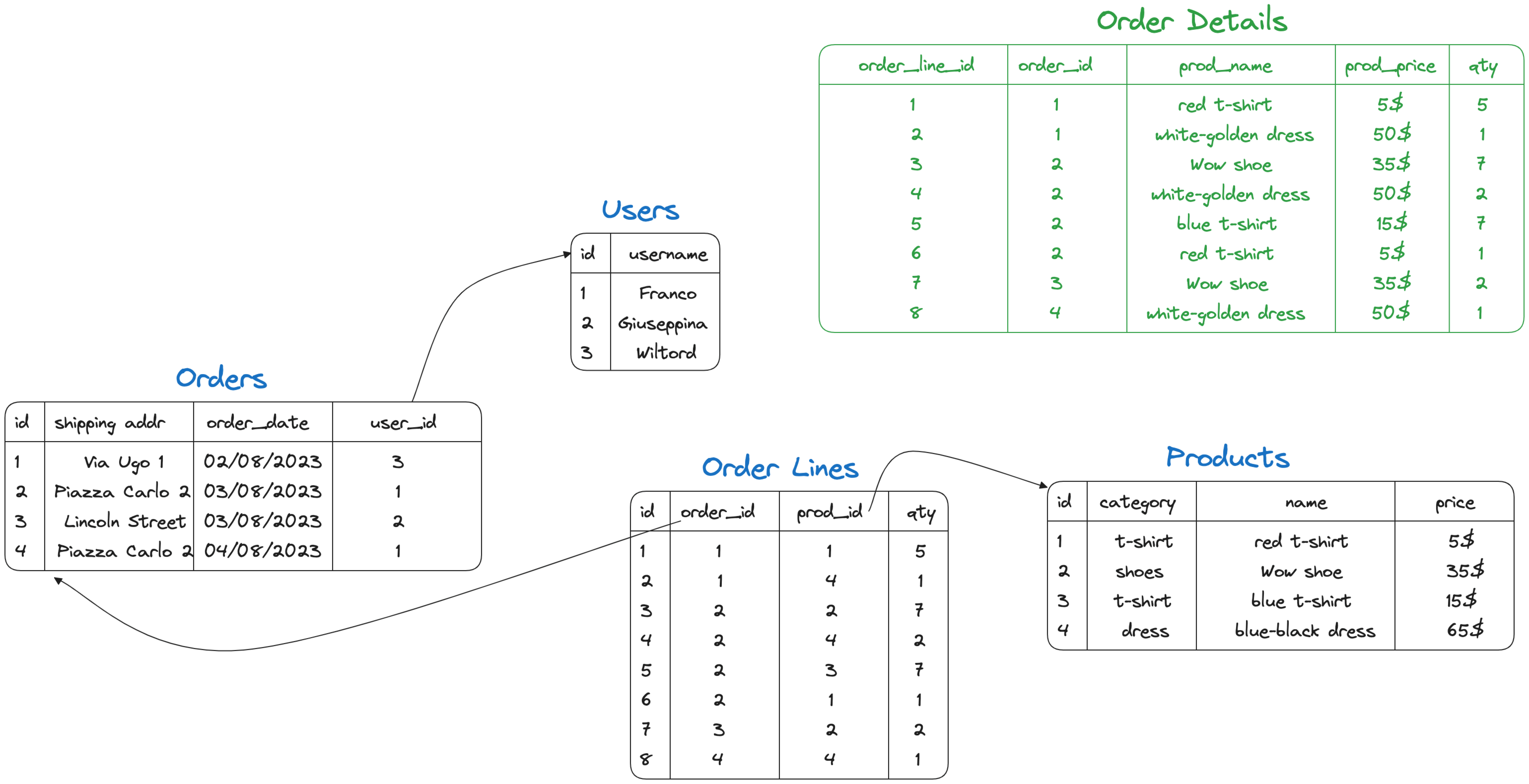
Add a new outbox table in PostgreSQL
How do we implement the outbox pattern in PostgreSQL? The first option is to add a new dedicated table and update it within the same transaction changing the ORDERS and ORDER_LINES tables. We can define the outbox table as follows:
CREATE TABLE ORDER_OUTBOX ( ORDER_LINE_ID INT, ORDER_ID INT, USERNAME TEXT, PRODUCT_NAME TEXT, PRODUCT_PRICE INT, QUANTITY INT );
We can then add the ORDER_OUTBOX table in the table.include.list parameter for the Debezium Connector to track its changes. The last part of the equation is to update the outbox table at every order: if Giuseppina wants 5 red t-shirts, the transaction will need to change the ORDERS, ORDER_LINES and ORDER_OUTBOX tables like the following:
BEGIN; INSERT INTO ORDERS (ID, SHIPPING_ADDR, ORDER_DATE, USER_ID) VALUES (5, 'Lincoln Street', '05/08/2023',2); INSERT INTO ORDER_LINES (ORDER_ID, PROD_ID, QTY) VALUES (5,1,5); INSERT INTO ORDER_OUTBOX SELECT ORDER_LINES.ID, ORDERS.ID, USERNAME, NAME PRODUCT_NAME, PRICE PRODUCT_PRICE, QTY QUANTITY FROM USERS JOIN ORDERS ON USERS.ID = ORDERS.USER_ID JOIN ORDER_LINES ON ORDERS.ID = ORDER_LINES.ORDER_ID JOIN PRODUCTS ON ORDER_LINES.PROD_ID = PRODUCTS.ID WHERE ORDERS.ID=5; END;
With this transaction and the Debezium configuration change to include the public.order_outbox table in the CDC, we end up with a new topic called mydebprefix.public.order_outbox. It has the following data, which represents the consistent situation in PostgreSQL:
{"before":null,"after":{"order_line_id":10,"order_id":5,"username":"Giuseppina","product_name":"red t-shirt","product_price":5,"quantity":5},"source":{"version":"2.5.0.Final.Aiven","connector":"postgresql","name":"mydebprefix","ts_ms":1733414963621,"snapshot":"false","db":"defaultdb","sequence":"[\"922748968\",\"922750584\"]","schema":"public","table":"order_outbox","txId":2297,"lsn":922750584,"xmin":null},"op":"c","ts_ms":1733414964217,"transaction":null}
This approach emits a new entry for every order line. We could also aggregate the outbox table at order level by, for example, adding the order lines information in a nested JSONB object.
Avoid the additional table with PostgreSQL logical decoding
The main problem with the outbox table approach is that we're storing the same information twice: once in the original tables and once in the outbox table. This doubles the storage needs, and the original applications that use the database generally not access it, making this an inefficient approach.
A better, transactional approach, is to use PostgreSQL logical decoding. Created originally for replication purposes, PostgreSQL logical decoding can also write custom information to the WAL log. Instead of re-storing the result of the joined data in another PostgreSQL table, we can emit the result as an entry to the WAL log. By doing it within a transaction, we can benefit from the transaction isolation therefore the entry in the log is committed only if the whole transaction is.
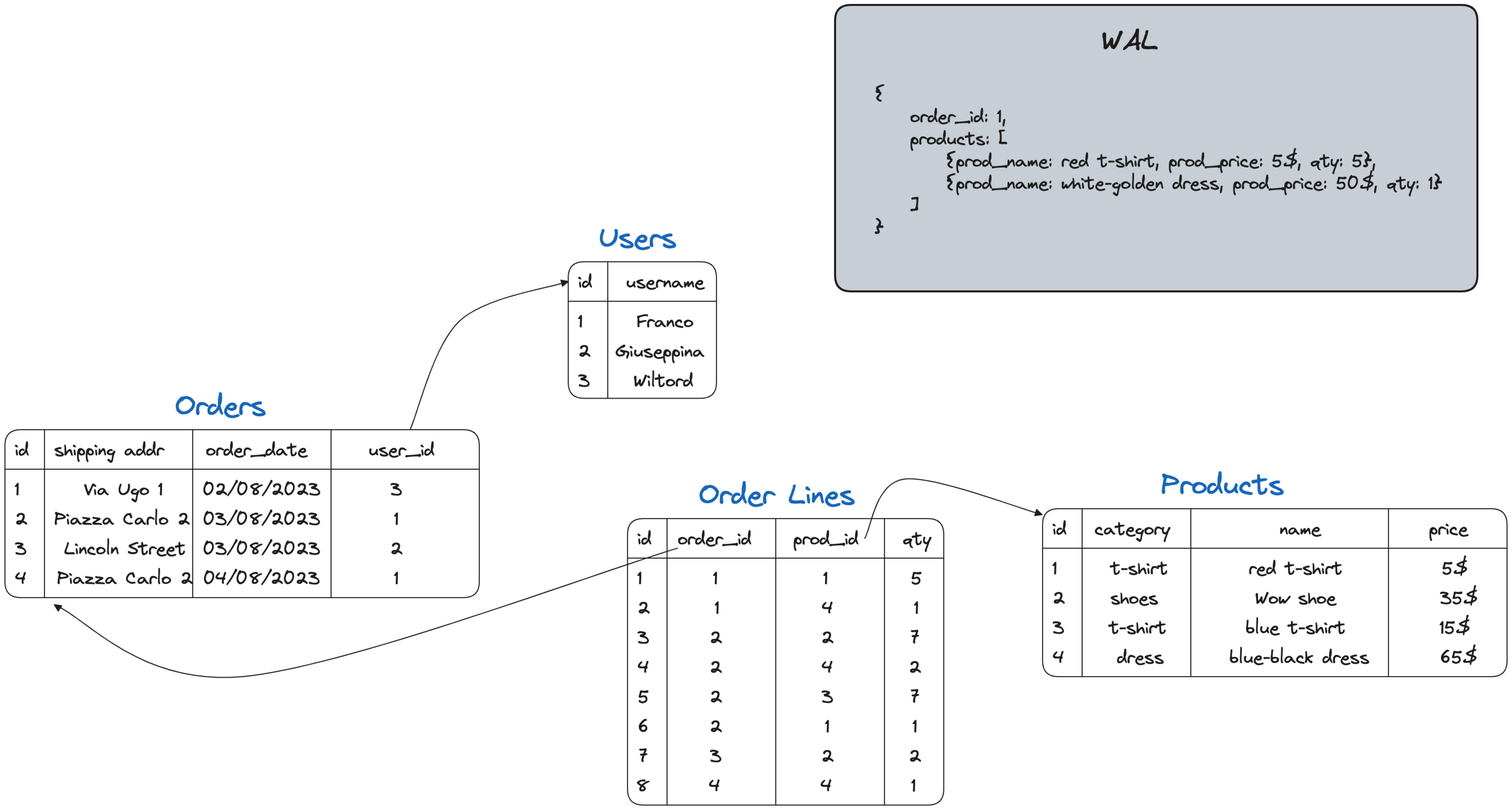
To use PostgreSQL logical decoding messages for our outbox pattern needs, we need to execute the following:
BEGIN; DO $$ DECLARE JSON_ORDER text; begin INSERT INTO ORDERS (ID, SHIPPING_ADDR, ORDER_DATE, USER_ID) VALUES (6, 'Via Ugo 1', '05/08/2023',3); INSERT INTO ORDER_LINES (ORDER_ID, PROD_ID, QTY) VALUES (6,4,2),(6,3,3); SELECT JSONB_BUILD_OBJECT( 'order_id', ORDERS.ID, 'order_lines', JSONB_AGG( JSONB_BUILD_OBJECT( 'order_line', ORDER_LINES.ID, 'username', USERNAME, 'product_name', NAME, 'product_price',PRICE, 'quantity', QTY))) INTO JSON_ORDER FROM USERS JOIN ORDERS ON USERS.ID = ORDERS.USER_ID JOIN ORDER_LINES ON ORDERS.ID = ORDER_LINES.ORDER_ID JOIN PRODUCTS ON ORDER_LINES.PROD_ID = PRODUCTS.ID WHERE ORDERS.ID=6 GROUP BY ORDERS.ID; SELECT * FROM pg_logical_emit_message(true,'myprefix',JSON_ORDER) into JSON_ORDER; END; $$; END;
In the above:
-
First we have two lines to insert the new order into the original tables
INSERT INTO ORDERS (ID, SHIPPING_ADDR, ORDER_DATE, USER_ID) VALUES (6, 'Via Ugo 1', '05/08/2023',3); INSERT INTO ORDER_LINES (ORDER_ID, PROD_ID, QTY) VALUES (6,4,2),(6,3,3); -
Next, we use
SELECTandJSONB_BUILD_OBJECTto:- get the new order details from the source tables
- create a unique JSON document (stored in the
JSON_ORDERvariable) for the entire order and store the results in an array for each line of the order
-
Finally, we need a
SELECTstatement to emit thatJSON_ORDERvariable as a logical message to the WAL file:SELECT * FROM pg_logical_emit_message(true,'myprefix',JSON_ORDER) into JSON_ORDER;pg_logical_emit_messagehas three arguments. The first,true, defines this operation as a part of a transaction.myprefixdefines the message prefix, andJSON_ORDERis the content of the message. -
The emitted JSON document should look similar to:
{"order_id": 6, "order_lines": [{"quantity": 2, "username": "Wiltord", "order_line": 19, "product_name": "blue-black dress", "product_price": 65}, {"quantity": 3, "username": "Wiltord", "order_line": 20, "product_name": "blue t-shirt", "product_price": 15}]}
If the above transaction is successful, we should see a new topic named mydebprefix.message that contains the logical message that we just pushed, the form should be the following:
{"op":"m","ts_ms":1690804437953,"source":{"version":"1.9.7.aiven","connector":"postgresql","name":"mydebmsg","ts_ms":1690804437778,"snapshot":"false","db":"defaultdb","sequence":"[\"822085608\",\"822089728\"]","schema":"","table":"","txId":8651,"lsn":822089728,"xmin":null},"message":{"prefix":"myprefix","content":"eyJvcmRlcl9pZCI6IDYsICJvcmRlcl9saW5lcyI6IFt7InF1YW50aXR5IjogMiwgInVzZXJuYW1lIjogIldpbHRvcmQiLCAib3JkZXJfbGluZSI6IDI1LCAicHJvZHVjdF9uYW1lIjogImJsdWUtYmxhY2sgZHJlc3MiLCAicHJvZHVjdF9wcmljZSI6IDY1fSwgeyJxdWFudGl0eSI6IDMsICJ1c2VybmFtZSI6ICJXaWx0b3JkIiwgIm9yZGVyX2xpbmUiOiAyNiwgInByb2R1Y3RfbmFtZSI6ICJibHVlIHQtc2hpcnQiLCAicHJvZHVjdF9wcmljZSI6IDE1fV19"}}
Where:
"op":"m"defines that the event is a logical decoding message"prefix":"myprefix"is the prefix we defined in thepg_logical_emit_messagecallcontentcontains the JSON document with the order details encoded based on thebinary.handling.modedefined in the connector definition.
If we use a mix of kcat and jq to showcase the data included in the message.content part of the payload with:
kcat -b KAFKA_HOST:KAFKA_PORT \ -X security.protocol=SSL \ -X ssl.ca.location=ca.pem \ -X ssl.key.location=service.key \ -X ssl.certificate.location=service.crt \ -C -t mydebprefix.message -u | jq -r '.message.content | @base64d'
We see the message in JSON format as:
{"order_id": 6, "order_lines": [{"quantity": 2, "username": "Wiltord", "order_line": 11, "product_name": "blue-black dress", "product_price": 65}, {"quantity": 3, "username": "Wiltord", "order_line": 12, "product_name": "blue t-shirt", "product_price": 15}]}
Conclusion
Defining a change data capture system allows downstream technologies to make use of the information assets is useful only if we can provide a consistent view on top of the data. The outbox pattern allows us to join data spanning different tables and provide a consistent, up to date view of complex queries.
PostgreSQL's logical decoding enables us to push such consistent view to Apache Kafka without having to write changes into an extra outbox table but rather by writing directly to the WAL log.
Further reading
Table of contents
- Change data capture across multiple tables with PostgreSQL® logical decoding messages and Debezium
- Use case: A PostgreSQL based online shop
- Start the Change Data Capture flow with the Debezium connector
- The consistency problem
- Recreate consistency in Apache Kafka
- Use the outbox pattern in PostgreSQL
- Add a new outbox table in PostgreSQL
- Avoid the additional table with PostgreSQL logical decoding
- Conclusion
- Further reading